Natural Language Processing • Word Vectors
- Overview
- What do you hope to learn in this course?
- Neural machine translation
- GPT-3: A first step on the path to universal models
- How do we represent the meaning of a word?
- Overview
- Word Vectors
- WordNet
- Word2Vec
- Limitations of Word Embeddings
- Citation
Overview

- After talking about human language and word meaning, we’ll introduce the ideas of the word2vec algorithm for learning word meaning.
- Going from there, we’ll kind of concretely work through how you can work out objective function gradients with respect to the word2vec algorithm.
- Next, we shall look into how optimization works.
- Finally, we develop a sense of how these word vectors work and what you can do with them.
- Key takeaway
- The really surprising result that word meaning can be represented not perfectly, but rather well by a large vector of real numbers gives a sense of how amazing deep learning word vectors are.
What do you hope to learn in this course?
- Okay, so I’m quickly, what do we hope to teach in this course. So we’ve got three primary goals.
- The first is to teach you the foundations I a good deep understanding
- Of the effect of modern methods for deep learning applied when or p. So we are going to start with and go through the basics and then go on to key methods that are used in NLP recurrent networks attention transformers and things like that.
- We want to do something more than just that. We’d also like to give you some sense of a big picture understanding of human languages and what are the reasons for why they’re actually quite difficult to understand produce even though human seems
- To add easily. Now obviously if you really want to learn a lot about this topic, you should enroll in and go and start doing some classes and the linguistics department. But nevertheless, for a lot of you. This is the only human language. p Content. You’ll see during your master’s degree or whatever. And so we do hope to spend a bit of time on that starting today.
- And then finally, we want to give you an understanding of an ability to build systems in PI torch for some of the major problems in NLP, so we’ll look at learning word meanings dependency parsing machine translation question answering.
Neural machine translation
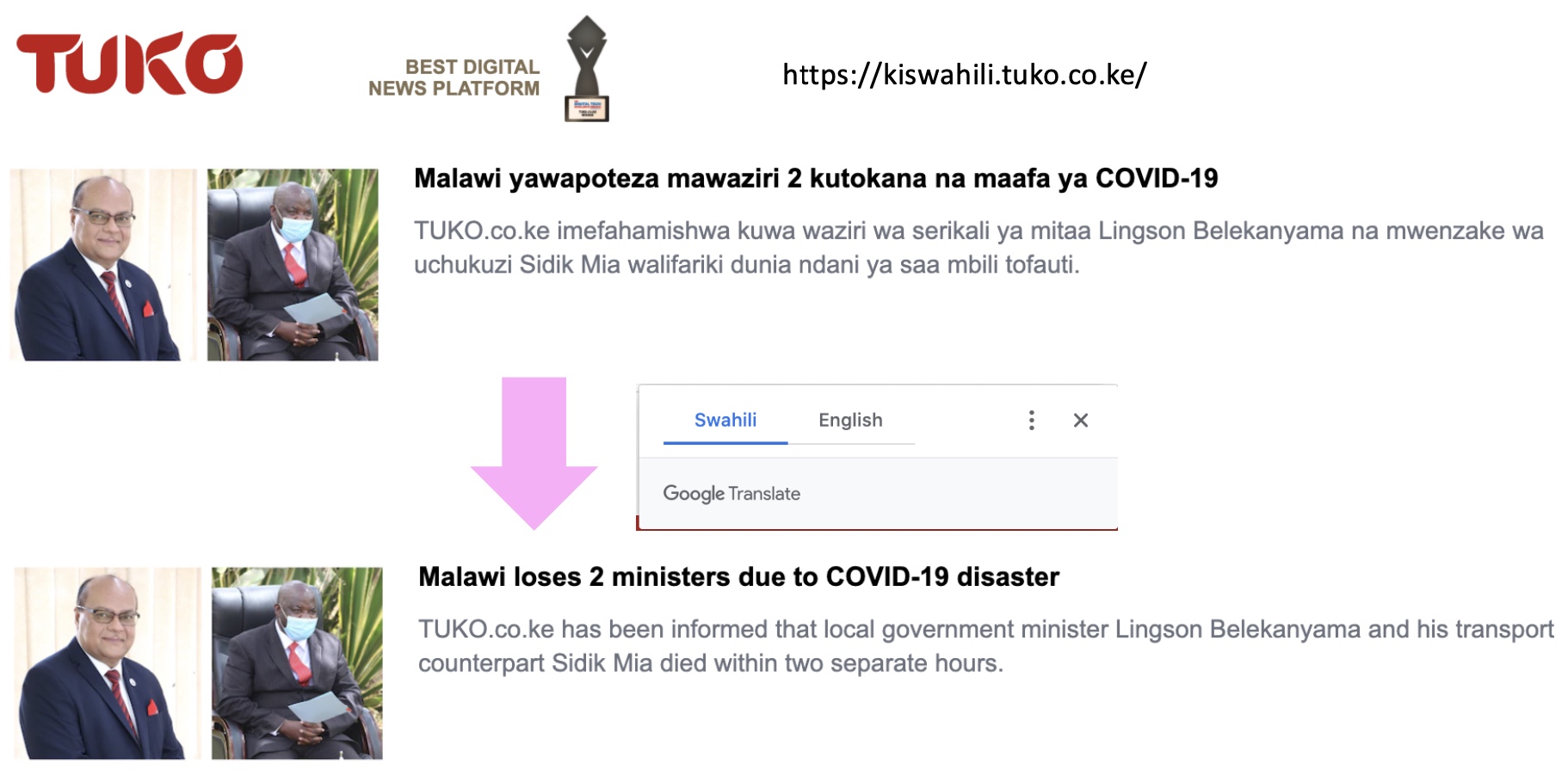
- In the last decade or so, and especially in the last few years, machine translation has advanced by leaps and bounds thanks to neural networks. Machine translation powered by neural nets is referred to as “neural machine translation”.
- This is outright amazing because for thousands of years, learning languages was a human task which required effort.
- But now we’re in a world where you could just hop on your web browser and think, “Oh, I wonder what the news is in Kenya today”. You can head off over to a Kenyan website and you can see something like this (cf. image above). You can then ask Google to translate it for you from Swahili. While the translation isn’t quite perfect, it’s reasonably good.
GPT-3: A first step on the path to universal models
- The single biggest development in NLP in the last year was GPT-3, which was a huge new model that was released by OpenAI.
- This is an exciting development because it’s a step on the path to universal models, where you can train up an extremely large model on an extensive dataset. Such models knowledge of how to do a variety of tasks and can be easily applied to a specific task at hand. So, we’re no longer building a model to detect spam or a model to detect foreign language content. Instead of building separate supervised classifies for every different task, we’ve now just built up a model that understands language and can do a variety of NLP-related tasks.

- In the image above, on the left, the model is being prompted to write about Elon Musk in the style of Dr. Seuss. We prompted the model with some text which led it to generate more text. The way it generates more texts is literally by just predicting one word at a time.
- This setup yields something very powerful because what you can do with GPT-3 is you can give it examples of what you’d like it to do.
- In the image above, on the upper right, the model is being prompted with a conversation between two people, starting with “I broke the window”. Now, change it into a question: “what did I break?”. Next, “I gracefully saved the day” - change it into a question - “what did I gracefully save?”. Feed in this prompt to GPT-3 so it understands what you’re trying to do.
- Now, if we give it another statement like “I gave John flowers”. I can then say, GPT-3 predict what words come next, and it will follow my prompt and produce “who did I give flowers to?”. Or you can say “I gave her a rose and a guitar”, and it will follow the idea of the pattern and output “who did I give a rose and a tattoo to?”.
- This one model can do an amazing range of NLP tasks given an example of the task.
- Let’s take the task of translating human language sentences into SQL as another example (cf. image above, lower right). You can give GPT-3 a prompt saying “how many users have signed up since the start of 2020?” and GPT-3 turns it into SQL! Or you can give it another query “the average number of influences each user subscribe to”. And again, GPT-3 converts that into SQL. This shows that GPT-3 learns patterns within language and is versatile to a range of tasks.
How do we represent the meaning of a word?

- How do we represent the meaning of a word? Well, let’s start with what is meaning. We can look up the Webster Dictionary and here’s what it says:
- The idea that is represented by a word, phrase, etc.
- The idea that a person wants to express by using word, signs, etc.
- The idea that is expressed in a work of writing, art, etc.
Overview
“You shall know a word by the company it keeps” - J.R. Firth
- Natural language processing (NLP) is a crucial part of artificial intelligence (AI), modeling how people share information.
- In recent years, deep learning approaches have obtained very high performance on many NLP tasks.
- Natural language processing (NLP) is the ability of a computer program to understand human language as it is spoken and written – referred to as natural language. It is a component of artificial intelligence (AI).
- NLP has existed for more than 50 years and has roots in the field of linguistics.
Word Vectors
- What is a word vector?
- They are word meanings stored in large vectors called “word vectors”.
- Word vectors or Word Embeddings build a dense vector for each word, chosen so that it is similar to vectors of words that appear in similar contexts.

- So why is it called word embeddings?

- Let’s take an example: the meaning of the word ‘banking’ is spread over all 300 dimensions of the vector. When placed together, the words are all in a high dimensional vector space and are embedded into that space as we can see in the image above.
- The word, however, needs to be represented by a vector. To transform a word into a vector, we turn to the class of methods called “word embedding” algorithms. These turn words into vector spaces that capture a lot of the meaning/semantic information of the words (e.g. king - man + woman = queen).
- Words with similar meanings tend to occur in similar context, and thus they capture similarity between words.
- Typically, word embeddings are pre-trained by optimizing an auxiliary objective in a large unlabeled corpus, such as predicting a word based on its context (Mikolov et al., 2013b, a), where the learned word vectors can capture general syntactic and semantic information.
- Thus, these embeddings have proven to be efficient in capturing context similarity, analogies and due to its smaller dimensionality, are fast and efficient in computing core NLP tasks.
- Measuring similarity between vectors is possible, using measures such as cosine similarity.
- Word embeddings are often used as the first data processing layer in a deep learning model, and we will build on this more as we get to talking about BERT.
- These embeddings have proven to be efficient in capturing context similarity, analogies and due to its smaller dimensionality, are fast and efficient in computing core NLP tasks.
WordNet
- One of the earliest ways a word’s meaning was tried to be stored was in WordNet.
- WordNet: it was a thesaurus containing lists of synonym sets and hypernyms (is a relationship), however it:
- failed to work
- was missing nuance
- was missing new meanings of words
- and was impossible to keep up to date
- it used distributional semantics, aka a words meaning is given by the words that frequently appear close to it.
- Word embeddings is what came after it and what still powers most of the NLP tasks we see today!
Word2Vec
Word2Vec algorithm showed that we can use a vector (a list of numbers) to properly represent words in a way that captures semantic or meaning-related relationships (e.g. the ability to tell if words are similar, or opposites, or that a pair of words like “Stockholm” and “Sweden” have the same relationship between them as “Cairo” and “Egypt” have between them) as well as syntactic, or grammar-based, relationships (e.g. the relationship between “had” and “has” is the same as that between “was” and “is”).
- These are bag of word models thus, they don’t account for context.
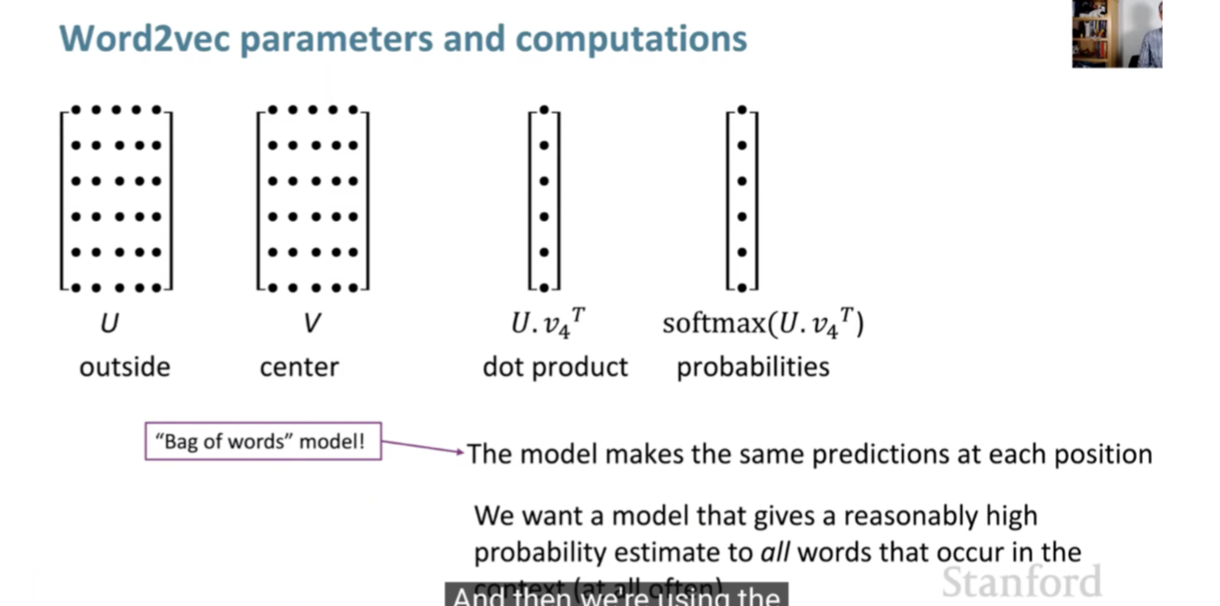
- But how does it work?
- Let’s say you have a corpus of text.
- Every word in a fixed vocabulary is represented by a vector.
- What we need to do is learn what a good vector is for each word.
- How do we learn good word vectors?
- Stochastic Gradient Descent (take a small batch and work out the gradient based off them) needed to minimize our cost function.
- How do we learn good word vectors?
- We take a center word \(c\), and words around it \(o\).
- Objective: for each position, we want to predict context words in a window and give high probability to words that occur within a context.
- Data likelihood is what we need to figure out. and we want to optimize the loss function.
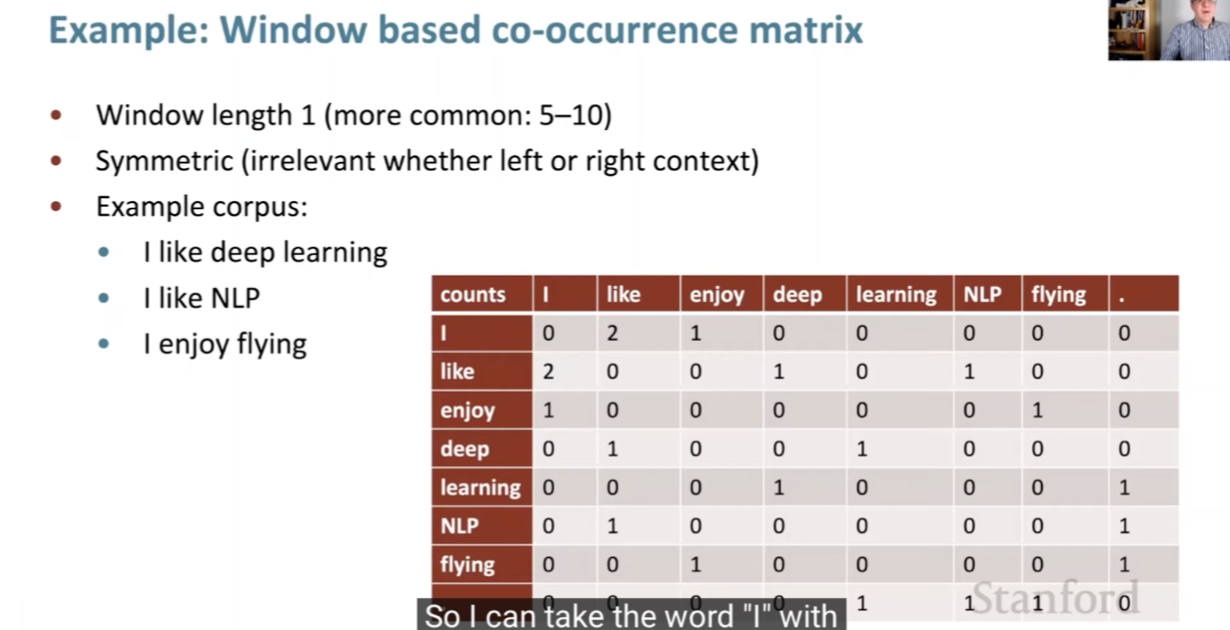
- These words within a window will have somewhat similar vectors.
- These are simple count co-occurrence vectors and the meaning components in these vectors are represented as a ratio of its co-occurrence probability.

- This embeds meaning within co-occurrence.
- Data likelihood is what we need to figure out. and we want to optimize the loss function.
- We will also have a softmax function at the end that maps arbitrary values \(x\) to a probability distribution \(p\). Probability is calculated by the dot product from center and context word vectors. We use the softmax score to convert into probabilities.
- So how do we make our word vectors?
- We want to try to get reduce the loss, which would mean we would maximize probability of actually getting word.
- Model parameters = word vectors
- For each word, we will have 2 vectors that are \(d\) dimensional for both center and surrounding words.
- These two vectors will change as you move through the sentence, you’ll keep a window.
- We place words that are similar in meaning, close together in a high dimensional vector space
- For example, bread and croissant are kind of similar:
- Other similar words to croissant: brioche, focaccia
- Another example, woman, king, man:
- Start at king, subtract male, add woman = Queen:
King - man + woman = Queen
- This shows that analogies are possible.
- Start at king, subtract male, add woman = Queen:
- For example, bread and croissant are kind of similar:
- Word2Vec can be implemented with two architectures:
- Skip-grams
- The skip-gram model does the exact opposite of the CBOW model, by predicting the surrounding context words given the central target word.
- CBOW:
- CBOW computes the conditional probability of a target word given the context words surrounding it across a window of size \(k\).

- CBOW computes the conditional probability of a target word given the context words surrounding it across a window of size \(k\).
- Skip-grams
- Note: the difference between traditional word count based models and deep learning based models is that deep learning based NLP models invariably represent their words, phrases and even sentences using these embeddings.
Limitations of Word Embeddings
- One limitation of individual word embeddings is their inability to represent phrases (Mikolov et al., 2013), where the combination of two or more words (e.g., idioms like “hot potato” or named entities such as “Boston Globe”) does not represent the combination of meanings of individual words.
- One solution to this problem, as explored by Mikolov et al. (2013), is to identify such phrases based on word co-occurrence and train embeddings for them separately.
- More recent methods have explored directly learning n-gram embeddings from unlabeled data (Johnson and Zhang, 2015).
- Training embeddings from scratch requires a large amount of time and resources. Mikolov et al. (2013) tried to address this issue by proposing negative sampling which is nothing but frequency-based sampling of negative terms while training the word2vec model.
- A common phenomenon for languages with large vocabularies is the unknown word issue or out-of-vocabulary word (OOV) issue.
- Character embeddings naturally deal with it since each word is considered as no more than a composition of individual letters.
- In languages where text is not composed of separated words but individual characters and the semantic meaning of words map to its compositional characters (such as Chinese), building systems at the character level is a natural choice to avoid word segmentation (Chen et al., 2015). Thus, works employing deep learning applications on such languages tend to prefer character embeddings over word vectors (Zheng et al., 2013).
- Traditional word embedding methods such as Word2Vec and Glove consider all the sentences where a word is present in order to create a global vector representation of that word.
- However, a word can have completely different senses or meanings in the contexts.
- For example, lets consider these two sentences:
- 1) “The bank will not be accepting cash on Saturdays”
- 2) “The river overflowed the bank.”
- The word senses of bank are different in these two sentences depending on its context. Reasonably, one might want two different vector representations of the word bank based on its two different word senses.
- The new class of models adopt this reasoning by diverging from the concept of global word representations and proposing contextual word embeddings instead.
- Let’s move on to the other topics to learn how we can improve upon these limitations.
Citation
If you found our work useful, please cite it as:
@article{Chadha2021Distilled,
title = {Word Vectors},
author = {Jain, Vinija and Chadha, Aman},
journal = {Distilled Notes for Stanford CS224n: Natural Language Processing with Deep Learning},
year = {2021},
note = {\url{https://aman.ai}}
}