Natural Language Processing • Transformers
Overview
- Please refer the Transformer primer for a detailed discourse on Transformers.
Transformers
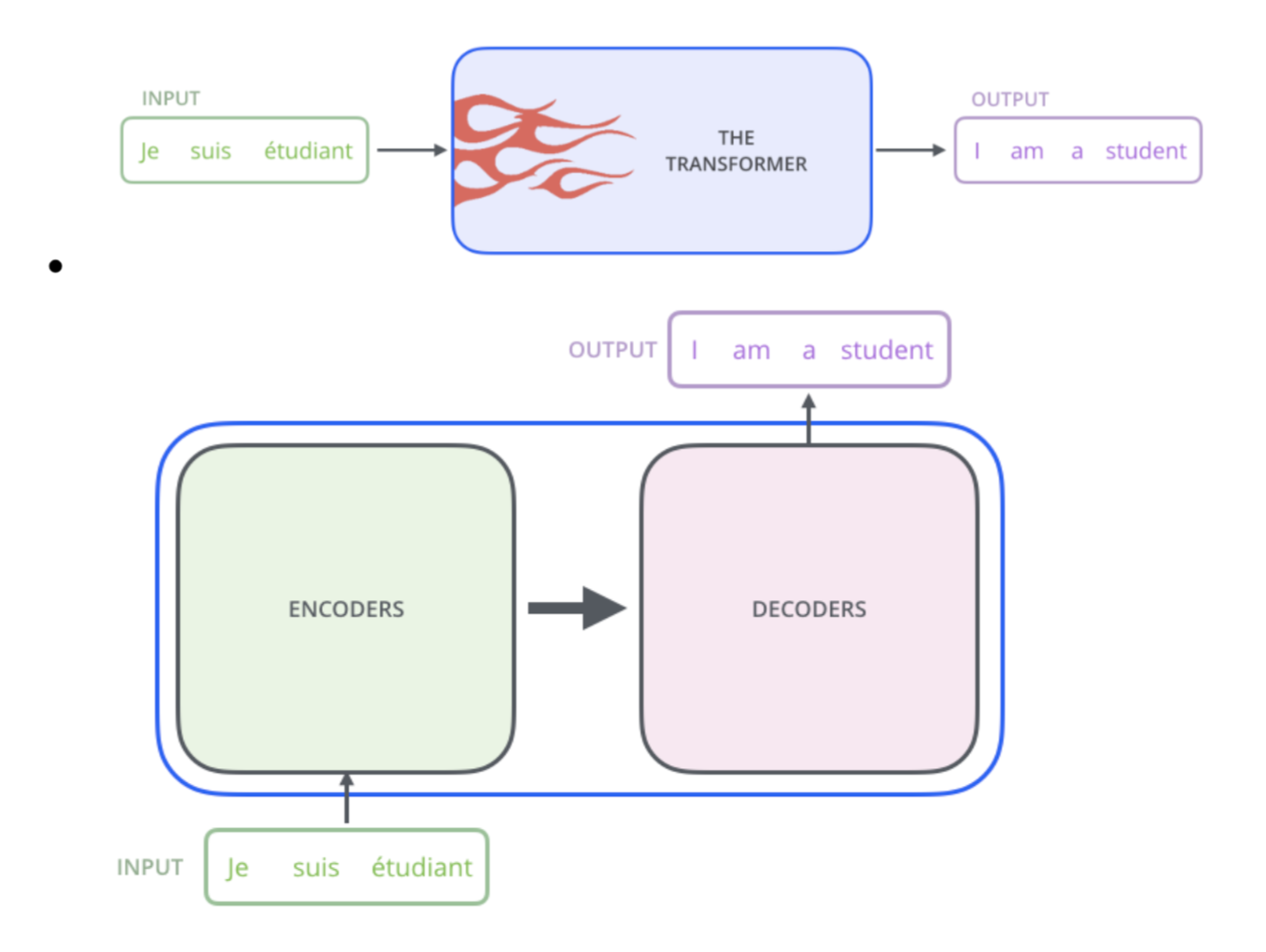
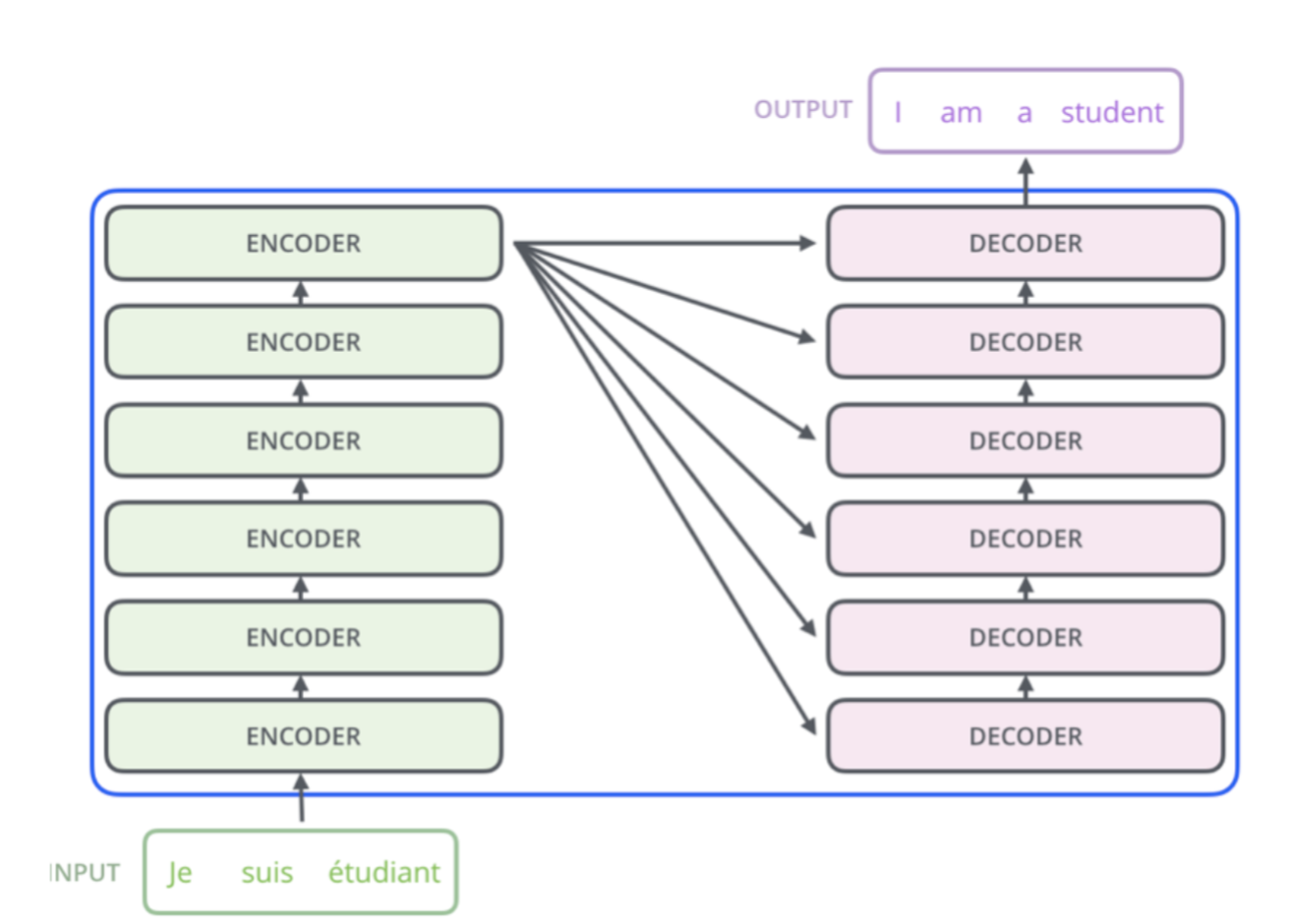
Layer normalization: trick to help models train faster
- Forward pass has variations and can be uninformative
- Scaled Dot Product: attention is a final variation to aid in Transformer training
- When dimensionality d becomes large, dot products between vectors tend to become large
- Because of this, inputs to the softmax function can be large, making the gradient small
Transformers cons
- Quadratic compute in self attention
- Quadratic compute:
- \(O(T^2d)\) where \(T\) is the sequence length and \(d\) is the dimensionality
- Linformer: key idea is to map seq len dimensions to a lower dimension space for values,keys
- BigBird
- RNN only grew linearly
- Position representation: are simple absolute indices the best we can do?
Transformer Pretraining
- All words not seen at test time are mapped to a single UNK token
- Byte pair encoding algorithm:
- Simple effective strategy for defining a sub word vocabulary
- Word2Vec will embed the same word, even with different meanings, in the same way as it holds no context
- Transformer Pretraining through language modeling:
- Train a neural network to perform language modeling on a large amount of text
- Save the network parameter
- Pretraining/Fine Tuning:
- Pretraining can improve NLP applications by serving as parameter initialization
- Pretrain on language modeling:
- Lots of text, learn general things
- Finetune on your task:
- Not many labels, adapt to the task
Pretrained Models
- Decoders: language models, what weve seen so far
- Nice to generate from, cant condition on future words
-
When we pretrain decoders, we can ignore that they were trained to model p(w w1) - Gradient back prop through whole network
- GPT
- Was a big success in pretrained decoder
- Transformer decoder with 12 layers
- 768 dimensional hidden states, 3072 dimensional feed forward hidden layers
- Byte pair encoding with 40,000 merges
- Natural language inference: label pairs of sentences as entailing/contradictory/neutral
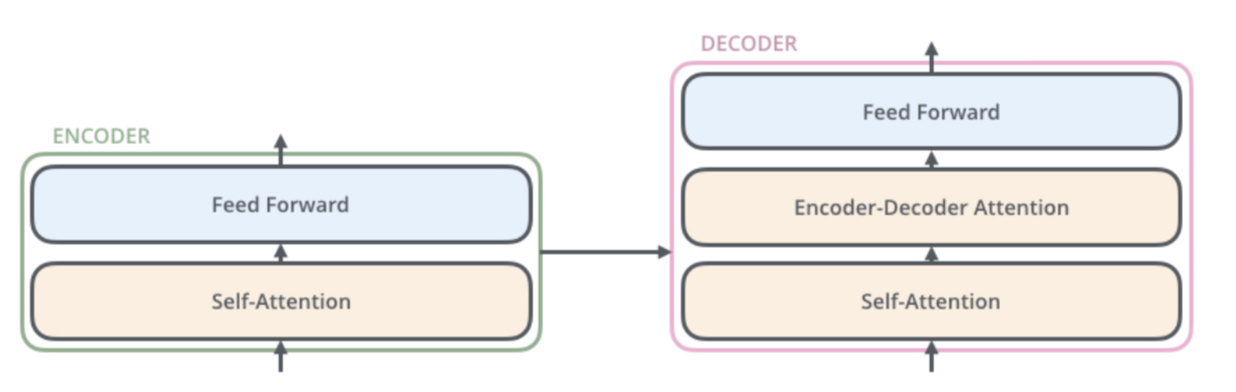
Encoders
- Gets bidirectional context
- Can condition on future
- How to pretrain them?
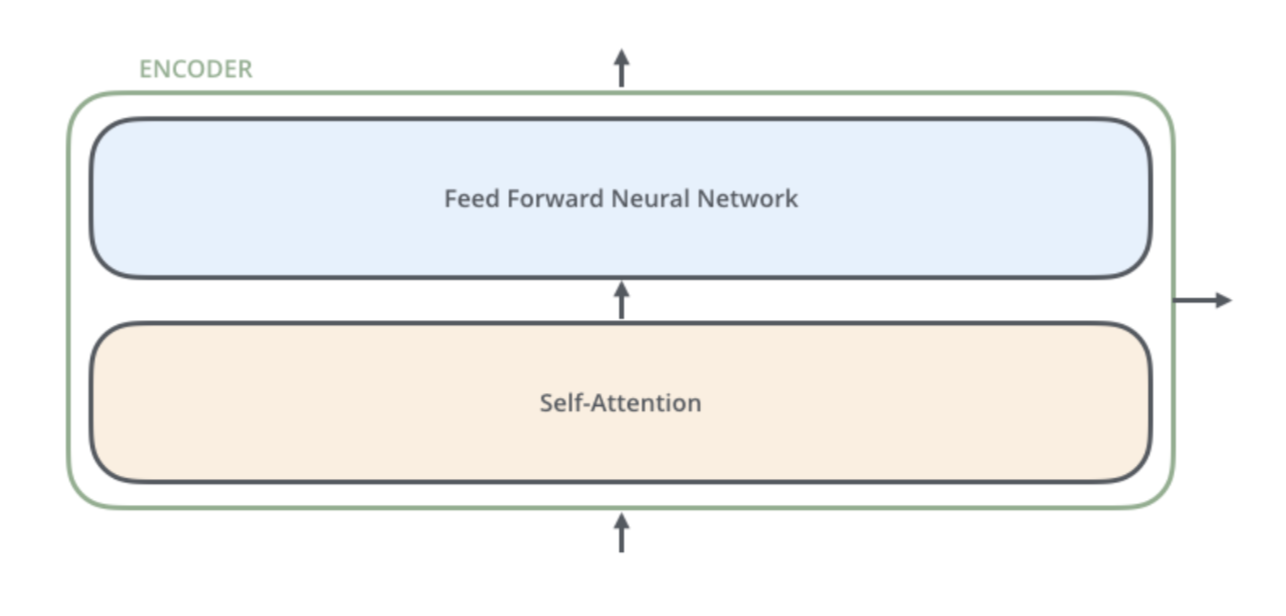
- Multi headed self attention
- Feed forward layers
- Layer norm
- No locality bias: long distance context has equal opportunity as short distance context. Benefit over LSTM
BERT
- Both BERT model sizes have a large number of encoder layers (which the paper calls Transformer Blocks) – twelve for the Base version, and twenty four for the Large version. These also have larger feedforward-networks (768 and 1024 hidden units respectively), and more attention heads (12 and 16 respectively) than the default configuration in the reference implementation of the Transformer in the initial paper (6 encoder layers, 512 hidden units, and 8 attention heads)
- Masked language modeling
- Idea: replace some fraction of words in the input with a special [MASK] token, predict these words
- MLM and Next sentence prediction
- You only need loss taken on the masked words that were predicted
- Next sentence prediction:512 words
- BERT-base and BERT-large
- Pretrain once, finetune many times
- Finetuning is common on a single GPU
- BERT for reading comprehension
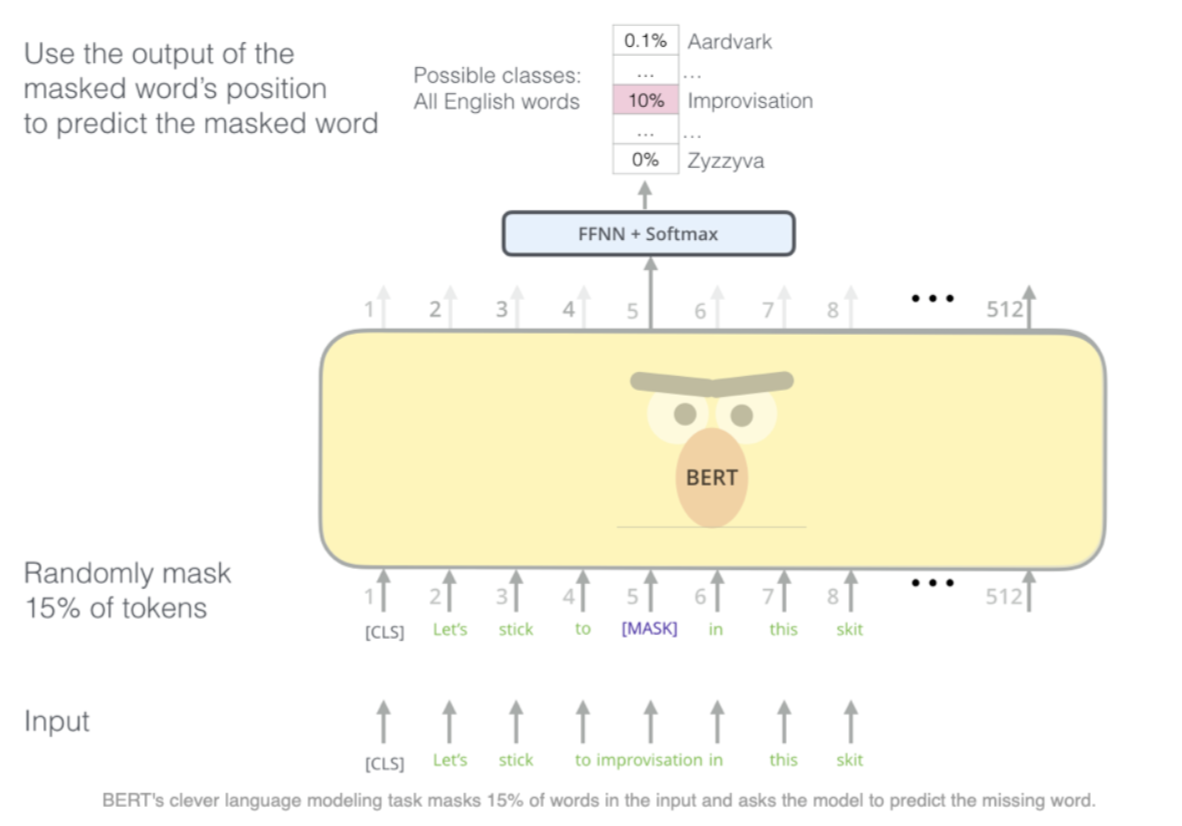
- Beyond masking 15% of the input, BERT also mixes things a bit in order to improve how the model later fine-tunes.
- Sometimes it randomly replaces a word with another word and asks the model to predict the correct word in that position.
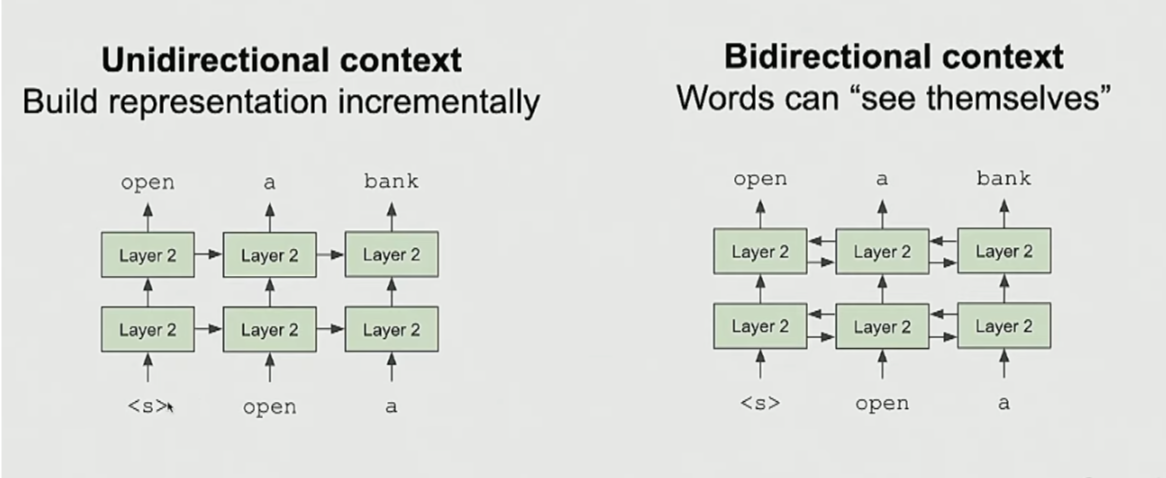
- Problem with GPT and ELMO:
- Only use left or right context or a concatenation of both, but not bidirectional.
- Unidirectional models.
- Works for predict the next word type of problems but words can’t see themselves in a bidirectional way.
- 512 dimension(seq of 512 words)
- Instead of training a normal language model, lets mask out \(k%\) of the words (15%)
- “The man went to
[MASK]to buy a[MASK]of milk” - Too little masking: too expensive to train because you’d need more data
- Too much masking: you’d mask out most of your context
- Mask token never seen at finetuning time
- NSP: to learn relationship between sentences, precinct whether Sentence B is actual sentence that proceeds Sentence A or a random sentence -Forcing model to make sentence level prediction
- Token embeddings, position embeddings, segment embeddings -BERT uses different pre-training tasks for language modeling. In one of the tasks, BERT randomly masks a percentage of words in the sentences and only predicts those masked words. In the other task, BERT predicts the next sentence given a sentence. This task in particular tries to model the relationship among two sentences which is supposedly not captured by traditional bidirectional language models.
- Consequently, this particular pre-training scheme helps BERT to outperform state-of-the-art techniques by a large margin on key NLP tasks such as QA, Natural Language Inference (NLI) where understanding relation among two sentences is very important.
- Fine tuning procedure:
- Sentiment analysis:
- Encode sentence with BERT
- Only parameters are final output matrix
- Positive, negative,netural 1000 * 3, so 3000 parameters
- 3000 new parameters and 300 million old ones
- Span prediction:
- Start of span, stop of span
- Sentiment analysis:
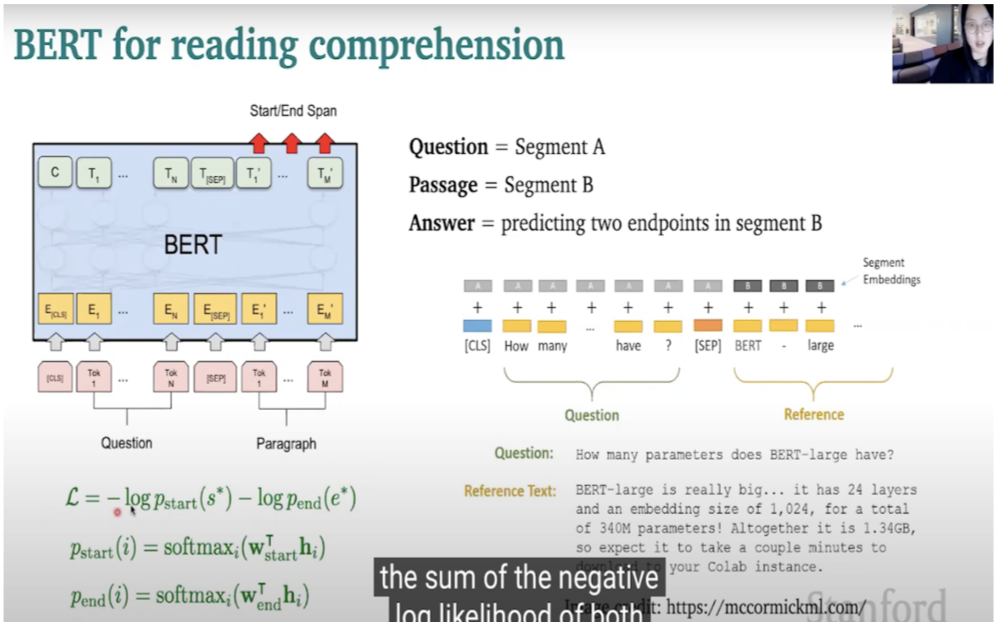
- Deep bidirectional Transformer encoder pretrained on a large amount of text
- Has 12 layers and 110 M parameters for BERT base
- BERT large has 24 layers and 330M parameters
- Question take as segment A
- Passage as segment B
- Answer is prediction of two endpoints in segment B
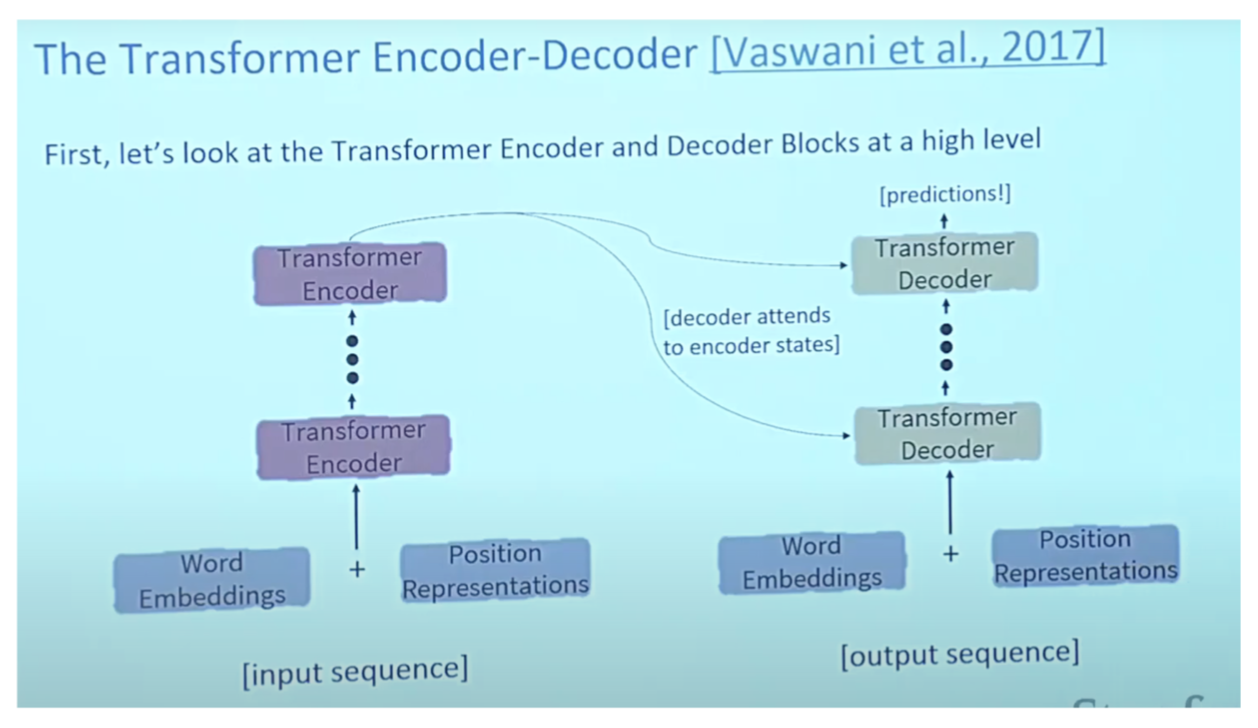
Encoder-Decoder
- What do we do to pretrain them
- Encoder portion benefits from bidirectionality
- The decoder you can use to train the model
T5 Language Model
- Transfer learning paradigm:
- Unlabeled text data, unsupervised objective, mask word and ask model to predict it
- After done this pre-training for a while, we fine tune this on a specific task (sentiment analysis task)
- Gets performance better rather than training from scratch
- 2018 string of papers kicked off excitement in field via transfer learning paradigm
- Given the current landscape of transfer learning for NLP, what works best? And how far can we push the tools we already have
- T5: take 2 sentences and predict a floating point number saying how similar they are like 3.8
- Turning regression into classification problem
- Transformer model originally proposed as encoder-decoder model
- Pretrain: BERT base sized encoder-decoder -> Denoising objective (masked dataset) -> use on C4 dataset
- Will Finetune:
- GLUE (NLU)
- SQuAD
- Will Finetune:
- Question: difference in transformer between encoder vs decoder vs encoder-decoder architecture
- One potential problem that the traditional encoder-decoder framework faces is that the encoder at times is forced to encode information which might not be fully relevant to the task at hand.
- The problem arises also if the input is long or very information-rich and selective encoding is not possible.
- For example, the task of text summarization can be cast as a sequence-to-sequence learning problem, where the input is the original text and the output is the condensed version.
- Intuitively, it is unrealistic to expect a fixed-size vector to encode all information in a piece of text whose length can potentially be very long.
- Similar problems have also been reported in machine translation
- In tasks such as text summarization and machine translation, certain alignment exists between the input text and the output text, which means that each token generation step is highly related to a certain part of the input text.
- This intuition inspires the attention mechanism. This mechanism attempts to ease the above problems by allowing the decoder to refer back to the input sequence. Specifically during decoding, in addition to the last hidden state and generated token, the decoder is also conditioned on a “context” vector calculated based on the input hidden state sequence.
Citation
If you found our work useful, please cite it as:
@article{Chadha2021Distilled,
title = {Transformers},
author = {Jain, Vinija and Chadha, Aman},
journal = {Distilled Notes for Stanford CS224n: Natural Language Processing with Deep Learning},
year = {2021},
note = {\url{https://aman.ai}}
}