Overview
- This section focuses on the significance of tokenization in Natural Language Processing (NLP) and how it enables machines to understand language.
- Teaching machines to comprehend language is a complex task. The objective is to enable machines to read and comprehend the meaning of text.
- To facilitate language learning for machines, text needs to be divided into smaller units called tokens, which are then processed.
- Tokenization is the process of breaking text into tokens, and it serves as the input for language models like BERT.
- The extent of semantic understanding achieved by models is still not fully understood, although it is believed that they acquire syntactic knowledge at lower levels of the neural network and semantic knowledge at higher levels (source).
- Instead of representing text as a continuous string, it can be represented as a vector or list of its constituent vocabulary words. This transformation is known as tokenization, where each vocabulary word in a text becomes a token.
Tokenization: The Specifics
- Let’s dive a little deeper on how tokenization even works today.
- To start off, there are many ways and options to tokenize text. You can tokenize by removing spaces, adding a split character between words or simply break the input sequence into separate words.
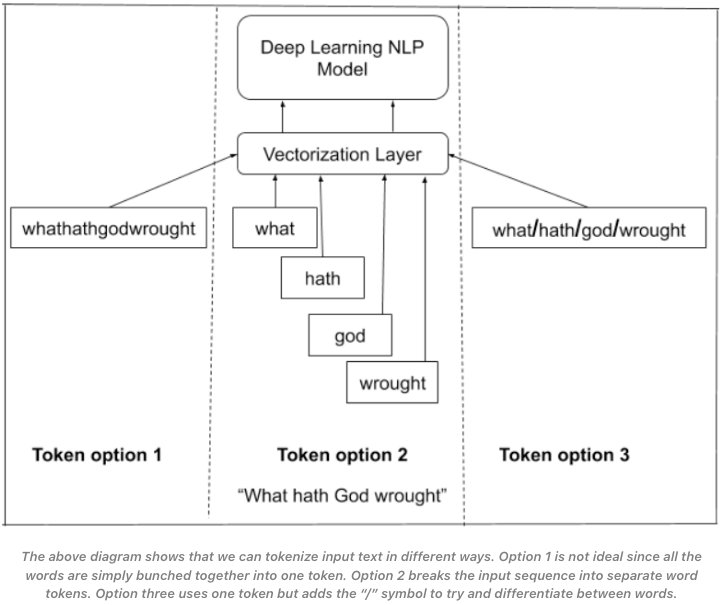
- This can be visualized by the image above (source).
- As we stated earlier, we use one of these options as a way to split the larger text into a smaller unit, a token, to serve as input to the model.
- Additionally, in order for the model to learn relationships between words in a sequence of text, we need to represent it as a vector.
- We do this in lieu or hard coding grammatical rules within our system as the complexity for this would be exponential since it would change per language.
- Instead, with vector representation, the model has encoded meaning in any dimension of this vector.
Sub-word Tokenization
- Sub-word tokenization is a method used to break words down into smaller sub-tokens. It is based on the concept that many words in a language share common prefixes or suffixes, and by breaking words into smaller units, we can handle rare and out-of-vocabulary words more effectively.
- By employing sub-word tokenization, we can better handle out-of-vocabulary words (OOV) by combining one or more common words. For example, “anyplace” can be broken down into “any” and “place”. This approach not only aids in handling OOV words but also reduces the model size and improves efficiency.
- Tokenizers are specifically designed to address the challenge of out-of-vocabulary (OOV) words by breaking down words into smaller units. This enables the model to handle a broader range of vocabulary.
- There are several algorithms available for performing sub-word tokenization, each with its own strengths and characteristics. These algorithms offer different strategies for breaking down words into sub-tokens, and their selection depends on the specific requirements and goals of the NLP task at hand.
Byte Pair Encoding (BPE)
- BPE is a type of sub-word tokenization that starts with a vocabulary of individual characters and iteratively merges the most frequently adjacent pair of symbols. BPE has been used in GPT-2 and RoBERTa.
- The algorithm starts with a set of individual characters as the initial sub-words.
- Then, it iteratively replaces the most frequent pair of bytes (or characters) in the text with a new, unused byte.
- This new byte represents the merged pair and is considered a new sub-word.
- This process is repeated for a fixed number of iterations or until a certain number of sub-words is reached.
- For example, consider the word “internationalization”. Using BPE, the algorithm would first identify the most frequent pair of bytes “in” and replace it with a new byte “A”. Next, it would identify the next most frequent pair “ter” and replace it with “B”, and so on.
- The resulting sub-words would be:
"in", "ter", "na", "ti", "on", "al", "i", "za", "t", "io", "n", "A", "B", "C", "D", "E", "F".
- BPE: Just uses the frequency of occurrences to identify the best match at every iteration until it reaches the predefined vocabulary size. (source)
- Pros: BPE helps to address the issue of OOV words and reduces the size of the vocabulary. It is also capable of encoding any word, no matter how rare.
- Cons: Similar to WordPiece, if the sub-word unit is not in the vocabulary, it further breaks it down, which can result in a loss of semantic meaning. Also, the frequency-based merging process in BPE might lead to sub-optimal results in some cases.
- BPE might break down the words into subwords based on common character sequences, like this:
["Chat", "G", "PT", " is", " an", " auto", "regressive", " language", " model"].
- The algorithm would learn the most frequent character sequences (“auto”, “ is”, etc.) and use them as tokens.
Unigram Sub-word Tokenization
- The algorithm starts by defining a vocabulary of the most frequent words and represent the remaining words as a combination of the vocabulary words.
- Then it iteratively splits the most probable word into smaller parts until a certain number of sub-words is reached.
- Unigram: A fully probabilistic model which does not use frequency occurrences. Instead, it trains a LM using a probabilistic model, removing the token which improves the overall likelihood the least and then starting over until it reaches the final token limit. (source)
WordPiece
- WordPiece is a sub-word tokenization algorithm that is used in models like BERT and DistilBERT. It starts with a base vocabulary of individual characters and then iteratively adds the most frequent and meaningful combinations of symbols to the vocabulary.
- The algorithm starts with a set of words, and then iteratively splits the most probable word into smaller parts. For each split, the algorithm assigns a probability to the newly created sub-words based on their frequency in the text. This process is repeated until a certain number of sub-words is reached.
- For example, consider the word “internationalization”.
- Using WordPiece, the algorithm would first identify the most probable word “international” and split it into “international” and “ization”.
- Next, it would identify the next most probable word “ization” and split it into “i” and “zation”. The resulting sub-words would be: “international”, “ization”, “i”, “zation”. Note: This example was generated by OpenAI’s ChatGPT.
- WordPiece: Similar to BPE and uses frequency occurrences to identify potential merges but makes the final decision based on the likelihood of the merged token. (source)
- Pros: WordPiece helps in reducing the vocabulary size and can effectively handle OOV words by breaking them down into known sub-words. It also aids in preserving semantic meaning as some subwords can stand as individual words.
- Cons: If the sub-word unit does not exist in the vocabulary, WordPiece further breaks it down into individual characters, which might result in loss of semantic meaning.
- In WordPiece, if “ChatGPT”, “autoregressive”, and “language model” are not in the vocabulary but their sub-words are, it might break them down into recognizable pieces:
["Chat", "##G", "##PT", "is", "an", "auto", "##re", "##gressive", "language", "model"].
- In this example, “##” denotes that the sub-word is part of a larger word and not a separate one.
SentencePiece
- SentencePiece, used in models like ALBERT and XLNet, is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabulary size is predetermined prior to the neural model training. SentencePiece implements both BPE and unigram language model with the extension of direct training from raw sentences.
- One of the main differences between SentencePiece and BPE is that SentencePiece is unsupervised, which means that it does not require any external training data.
- It is able to learn the sub-word units directly from the input text.
- SentencePiece also has a built-in mechanism for handling out-of-vocabulary words.
- It can generate new sub-word units on the fly for words that are not present in the initial vocabulary.
- Additionally, SentencePiece can handle multiple languages with a single model and can also be used for text normalization.
- SentencePiece is widely used in modern transformer-based models such as BERT, RoBERTa, and GPT-3.
- These models use SentencePiece to segment the input text into sub-word units, which allows them to handle out-of-vocabulary words and to reduce the model size.
- Pros: SentencePiece does not require pre-tokenization. It also overcomes the language dependency as it can be used for any language. Since it treats the input as a raw input string, it does not require language-specific pre/post-processing.
- Cons: It could lead to inefficient encoding for languages with many multi-byte characters (e.g., Asian languages), as it treats each Unicode character as a potential token.
Comparative Analysis Summary
- Below is a comparative analysis of the aforementioned four algorithms.
Byte-Pair Encoding (BPE)
- It starts with a set of individual characters as the initial subwords.
- It iteratively replaces the most frequent pair of bytes (or characters) in the text with a new, unused byte.
- It is a supervised algorithm, it needs external training data.
- It is widely used and have been proven to have good results in various NLP tasks.
Unigram Subword Tokenization
- It starts with a set of words, and then iteratively splits the most probable word into smaller parts.
- It assigns a probability to the newly created subwords based on their frequency in the text.
- It is less popular compare to other subword tokenization methods like BPE or SentencePiece.
- It has been reported to have good performance in some NLP tasks such as language modeling and text-to-speech.
WordPiece
- It starts with a set of words, and then iteratively splits the most probable word into smaller parts.
- It assigns a probability to the newly created subwords based on their frequency in the text.
- It is less popular compare to other subword tokenization methods like BPE or SentencePiece.
- It has been used in some NLP models such as Google’s Neural Machine Translation (GNMT) system.
SentencePiece
- It is based on the byte-pair encoding (BPE) algorithm.
- It is unsupervised, which means that it does not require any external training data.
- It has a built-in mechanism for handling out-of-vocabulary words.
- It can handle multiple languages with a single model and can also be used for text normalization.
- It is widely used in modern transformer-based models such as BERT, RoBERTa, and GPT-3.
References