Natural Language Processing • Neural Networks
- Overview
- Recurrent Neural Networks
- Long short term memory (LSTMs)
- Problems with RNN
- Deep Learning Classifiers
- Regularization
- Xavier initialization
- Optimizers
- Convolutional Neural Nets (CNNs)
- References
- Citation
Overview
- Neural networks are a subset of machine learning and are at the heart of deep learning algorithms.
- Their name and structure are inspired by the human brain, mimicking the way that biological neurons signal to one another.
- They are used in a variety of applications in financial services, from forecasting and marketing research to fraud detection and risk assessment.
- Neural networks with several process layers are known as “deep” networks and are used for deep learning algorithms.
Recurrent Neural Networks
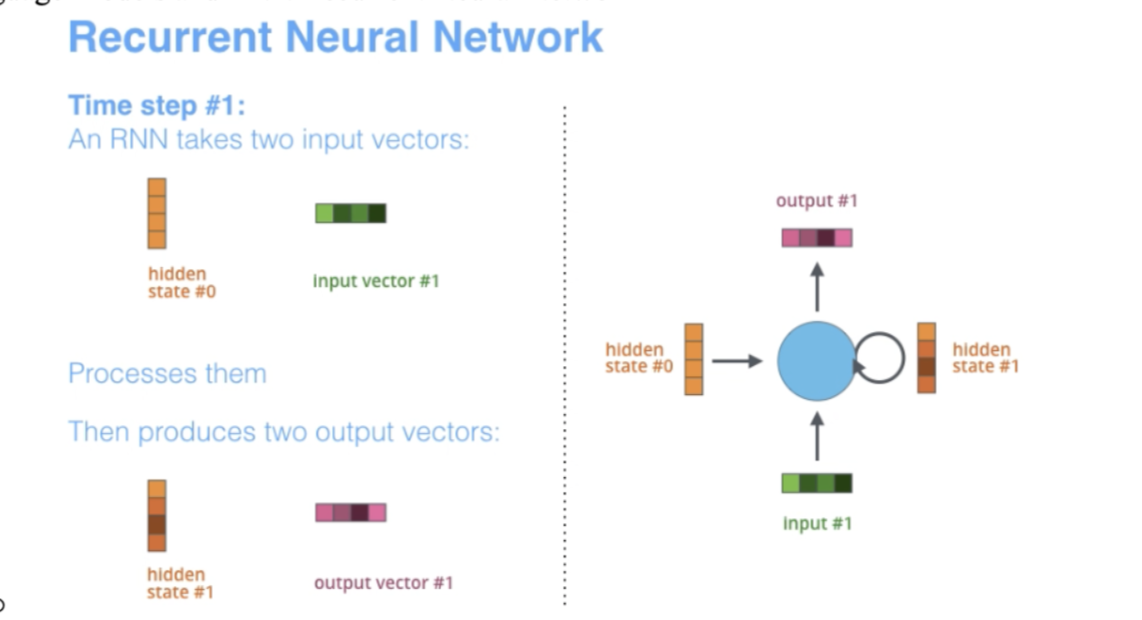
- The term “recurrent” applies as they perform the same task over each instance of the sequence such that the output is dependent on the previous computations and results.
- Generally, a fixed-size vector is produced to represent a sequence by feeding tokens one by one to a recurrent unit.
- In a way, RNNs have “memory” over previous computations and use this information in current processing.
- This template is naturally suited for many NLP tasks such as language modeling.
- RNNs are tailor-made for modeling context dependencies in language and similar sequence modeling tasks, which resulted to be a strong motivation for researchers to use RNNs over CNNs in these areas.
- An example here is finding the difference in meaning between “dog” and “hot dog”.
- Another factor aiding RNN’s suitability for sequence modeling tasks lies in its ability to model variable length of text, including very long sentences, paragraphs and even documents (Tang et al., 2015).
- Unlike CNNs, RNNs have flexible computational steps that provide better modeling capability and create the possibility to capture unbounded context. This ability to handle input of arbitrary length became one of the selling points of major works using RNNs.
- RNN’s ability to summarize sentences led to their increased usage for tasks like machine translation (Cho et al., 2014) where the whole sentence is summarized to a fixed vector and then mapped back to the variable-length target sequence.
- While RNNs try to create a composition of an arbitrarily long sentence along with unbounded context, CNNs try to extract the most important n-grams.
- Although they prove an effective way to capture n-gram features, which is approximately sufficient in certain sentence classification tasks, their sensitivity to word order is restricted locally and long-term dependencies are typically ignored.
- A challenging task in NLP is generating natural language, which is another natural application of RNNs. Conditioned on textual or visual data, deep LSTMs have been shown to generate reasonable task-specific text in tasks such as machine translation, image captioning, etc. In such cases, the RNN is termed a decoder.
- Have a hidden layer, maintain it over time and feed it back to itself and keep it updated.
- Predict second word, feed in hidden layer from first word to help.
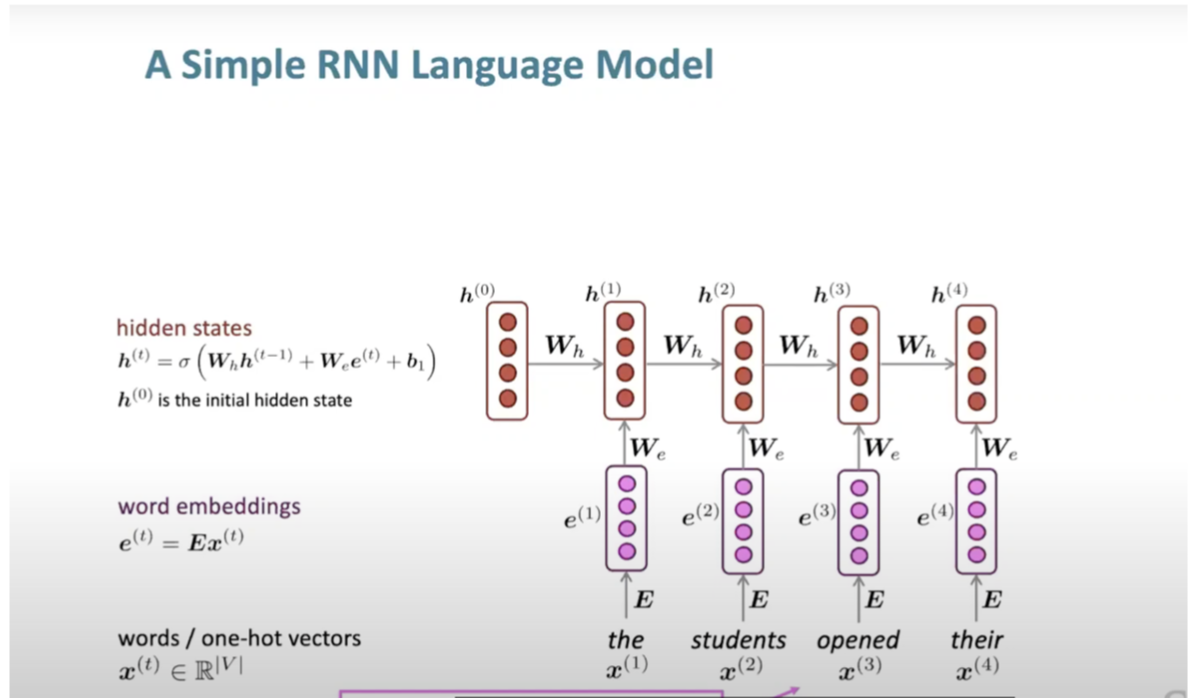
Training an RNN Language Model
- Let’s talk over a high-level overview on how to train a RNN language model:
- We start by getting a big corpus of text, as we do with most NLP applications.
- Feed that into RNN-LM and compute output distribution for every step.
- Train our model by assessing how good of a job we did with cross entropy loss.
- Average this to get overall loss for entire training set.
- Note, we cut corpus into pieces in practice, so we compute loss on small chunk of data.
- Keep in mind these specific training steps:
- We use backpropagation and update parameters.
- Take our loss and backprop it.
- We run backpropogation over timesteps, thus summing gradients as you go = back prop through time.
Generate text with RNN
- By repeated sampled output becomes next steps input.
- Softmax as the last layer.
- Begin of seq special symbol.
- End of seq special symbol.
Long short term memory (LSTMs)
- Two problems with RNNs are the vanishing and exploding gradient problem.
- Vanishing: Model never learns information from far away that it can use in future.
- Exploding: gradient becomes too big then Stochastic gradient descent update step becomes too big.
- This can cause a bad update as you will take a very large step.
- Gradient clipping solution for exploding gradient.
- Take a step in same direction but take smaller step.
- So how is it different from traditional RNN?
- Rather than just one hidden vector in RNN, we will build 2 hidden states.
- Hidden state and cell state.
- Cell stores long term information.
- LSTM can read, erase and write from the cell.
- Controlled by gates which are also vectors with open 1 or closed 0.
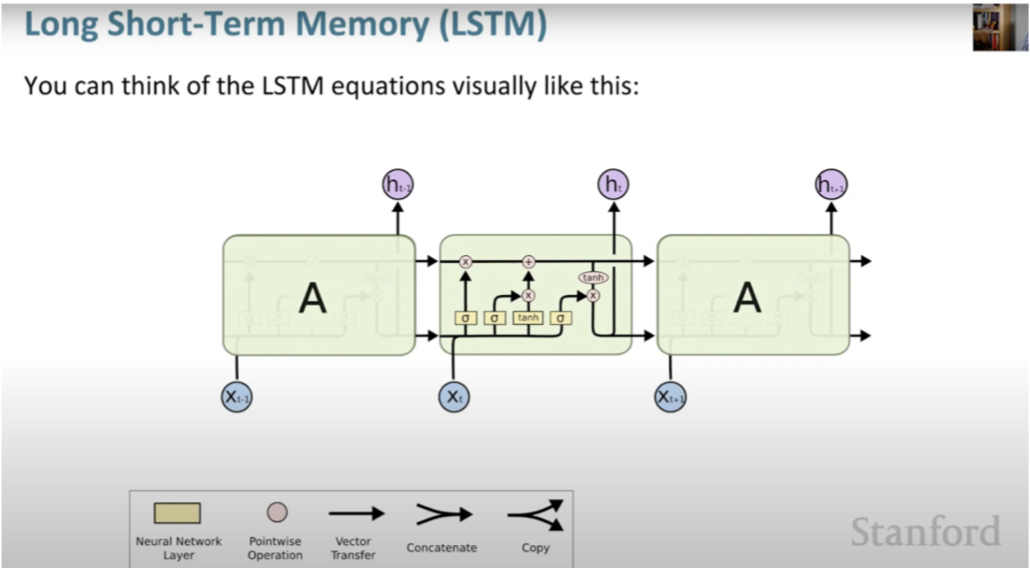
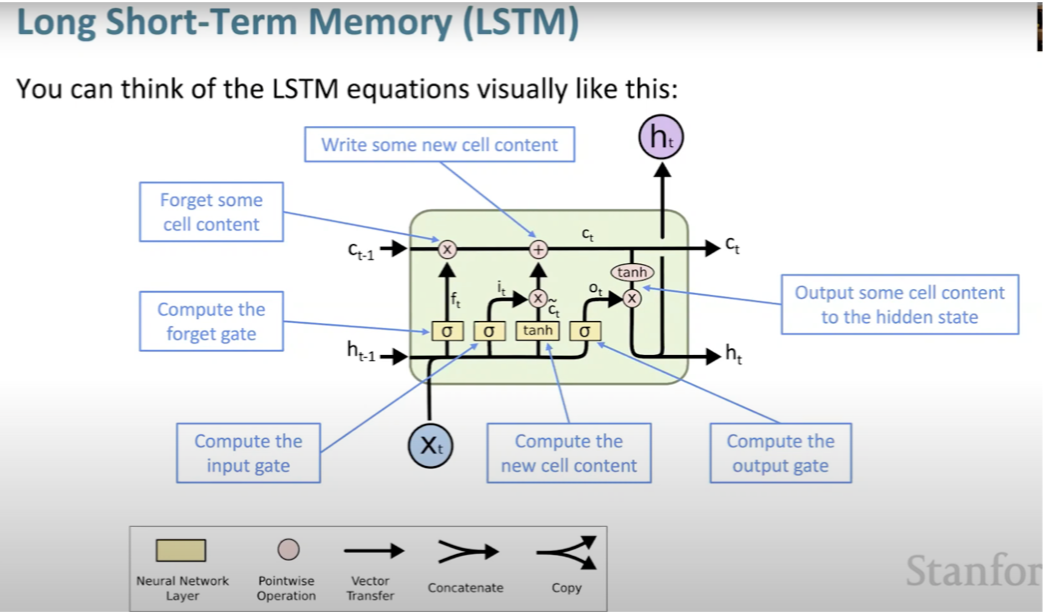
- LSTM makes it easier for RNN to preserve information over many timesteps.
- They have long distance dependencies.
- Gates are learned as well via back prop.
- Bi directional and multi layer RNN:
- Sentiment classification.
- Backward RNN and Forward RNN concatenating their results.
- Only applicable if you have entire input sequence.
- BERT is a powerful pretrained contextual representation system built on bidirectionality.
Problems with RNN
- Linear interaction distance.
- Encodes linear locality:
- Nearby words often affect each others meaning.
- Problem: RNNs take \(O(sequence\,length)\) steps for distant word pairs to interact.
- Lack of parallelizability.
- Forward and backward passes have %%O(sequence\,length)5% non parallelizable operations.
- Inhibits training on very large datasets.
- If not recurrence, how about word window?
- Word window model will aggregate local contexts.
- 1D convolution.
- Number of unparallelled operations does not increase with seq length.
- Problem with long distance dependencies.
- Can stack word window layers to allow interaction between farther words.
Deep Learning Classifiers
- Let’s quickly talk about deep learning classifiers because unlike what we’ve seen before, these are non-linear classifiers.
- As we saw earlier, softmax classifier assigns classes based on inputs via probability.
- Traditional ML classifiers: Naive Bayes, SVM, logistic regression and softmax classifier are not very powerful classifiers as they only give linear decision boundaries.
- However these are unhelpful when the problem is complex.
- Neural classifiers will be much more powerful as they will have non-linear boundaries.
- At the top layer, they still have a softmax classifier which is still linear classifier, but below that is other layers of neural networks.
- These are simple feed forward multi class classifier:
- k-Nearest Neighbors
- Decision Trees
- Naive Bayes
- Random Forest
- Gradient Boosting
Regularization
- When we are building these neural networks with large parameters, so all models will need to regularize their loss function.
- A full loss function includes regularization over all parameters.
- For example: L2 regularization
- Only make parameters non 0 if they are useful.
- Works to prevent overfitting when we have a lot of features.
- Need regularization to make sure your models generalize well when we have a big model.
Dropout
- It’s a way of implementing regularization to reduce overfitting by preventing complex co-adaptations on training data.
- Let’s talk about how it works internally now:
- Time that you are training your model, for each batch in your training, then for each neuron in your model, you drop 50% of your input.
- Then at test time, you don’t drop model weights, you keep them all.
- It is a strong regularizer, that can learn a feature dependent regularization.
Xavier initialization
- You don’t want to start neural network parameter initialization of weights with zero.
- You will need random values to avoid symmetries.
Optimizers
- Usually plain Stochastic Gradient Descent is enough for training but will require hand tuning of learning rates
- You can just use a constant learning rate, not too big otherwise model can diverge and not too small as it can take too long
- Half the learning rate after each epoch
- You don’t want to pass through the data in the same order each time, you want to shuffle the data
Convolutional Neural Nets (CNNs)
- Main CNN/ConvNet idea:
- What you’re going to do is compute vectors for every word of a certain length.
- Compute vector based on subsequence of words.
- The need arose for an effective feature function that extracts higher-level features from constituting words or n-grams.
- These abstract features would then be used for numerous NLP tasks such as sentiment analysis, summarization, machine translation, and question answering (QA).
- CNNs turned out to be the natural choice given their effectiveness in computer vision tasks.
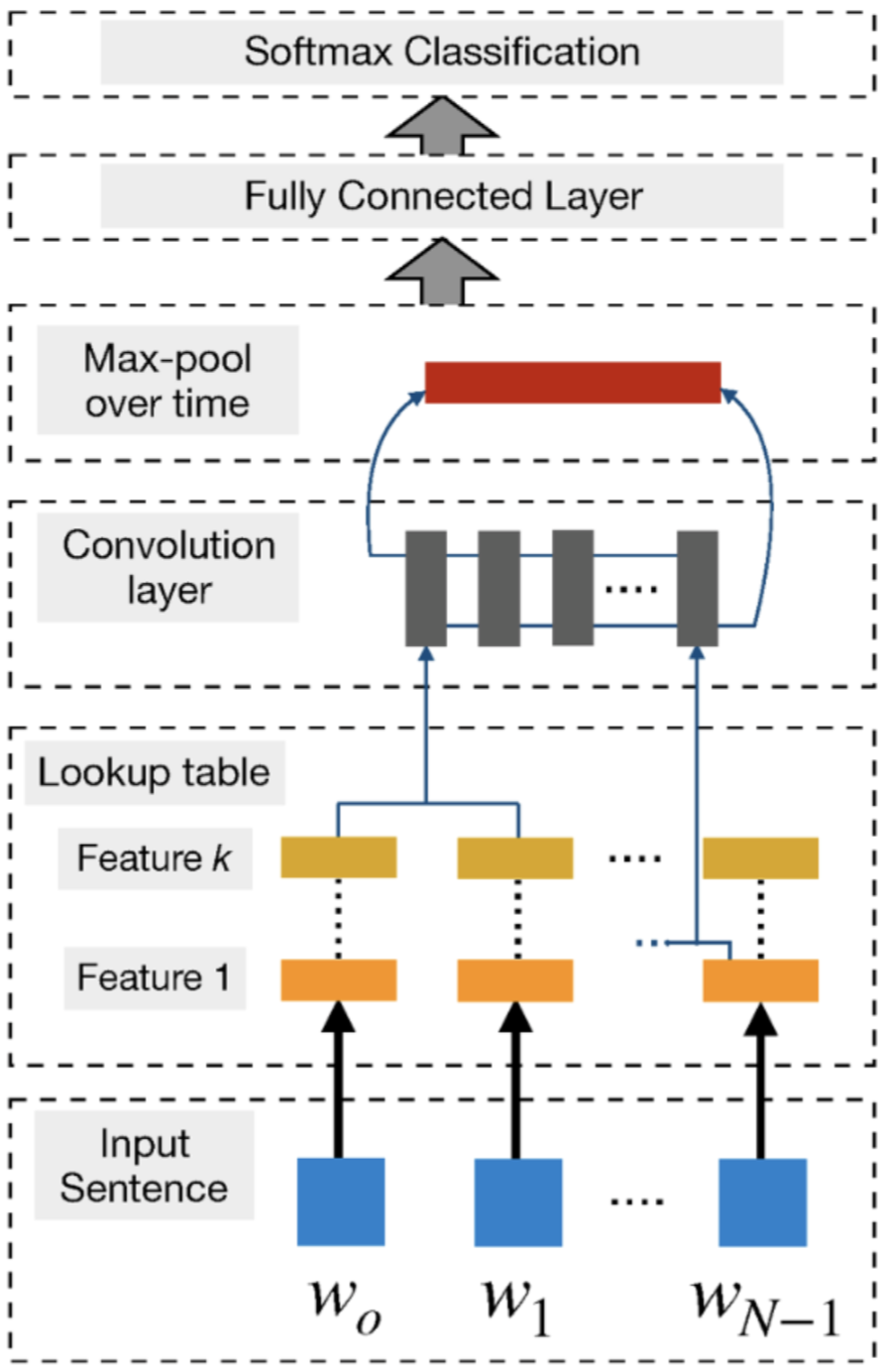
- CNNs have the ability to extract salient n-gram features from the input sentence to create an informative latent semantic representation of the sentence for downstream tasks
- In a CNN, a number of convolutional filters, also called kernels (typically hundreds), of different widths slide over the entire word embedding matrix.
- Each kernel extracts a specific pattern of n-gram. A convolution layer is usually followed by a max-pooling strategy.
- This strategy has two primary reasons.
- Firstly, max pooling provides a fixed-length output which is generally required for classification.
- Thus, regardless the size of the filters, max pooling always maps the input to a fixed dimension of outputs.
- Secondly, it reduces the output’s dimensionality while keeping the most salient n-gram features across the whole sentence.
- This is done in a translation invariant manner where each filter is now able to extract a particular feature (e.g., negations) from anywhere in the sentence and add it to the final sentence representation.
- Firstly, max pooling provides a fixed-length output which is generally required for classification.
References
- Named Entity Recognition with NLTK and SpaCy
- What is named entity recognition (NER) and how can I use it?
- Dependency Parsing in Natural Language Processing with Examples
Citation
If you found our work useful, please cite it as:
@article{Chadha2021Distilled,
title = {Neural Nets},
author = {Jain, Vinija and Chadha, Aman},
journal = {Distilled Notes for Stanford CS224n: Natural Language Processing with Deep Learning},
year = {2021},
note = {\url{https://aman.ai}}
}