Natural Language Processing • Knowledge Graphs
Overview
- Add Knowledge to Language Models:
- Standard language models: task to predict next word in seq of texts and can compute the probability of a sequence
- Masked language models(BERT): instead predict a masked token in a sequence of texts using bidirectional context
- Language models not always able to predict correctly:
- Unseen facts: some facts may not have occurred in the training corpus at all
- It can’t make up facts about the world
- Rare facts: LM hasn’t seen enoch examples during training to memorize the fact
- Model sensitivity: LM may have seen the fact during training, but is sensitive to the phrasing of the prompt
- Inability to reliably recall knowledge is a key challenge facing LM’s today
Knowledge Graphs
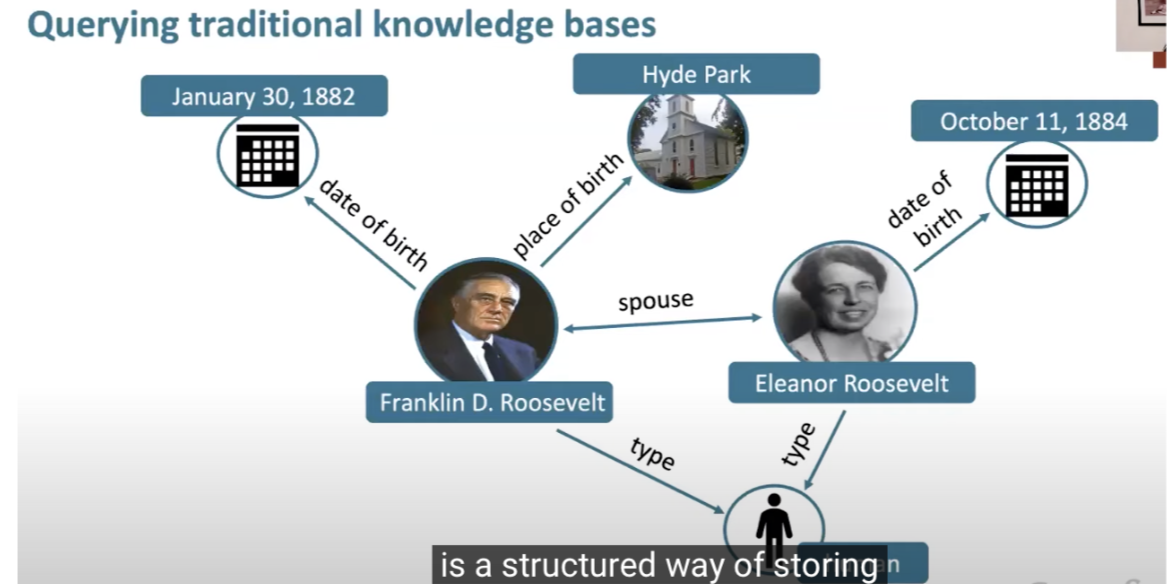
- Hope to replace SQL with natural question answering in terms of gaining knowledge
- Advantages of language models over traditional Knowledge Bases (SQL)
- LMs are pre trained over a large amounts of unstructured and unlabeled text
- Can support more flexible natural language queries
- Cons:
- Hard to interpret(why did it return that answer)
- Knowledge is encoded into the parameters of the model so its hard to understand
- Hard to trust(LM may product realistic but incorrect answers)
- Hard to modify(not easy to remove or update knowledge in the LM)
- Hard to interpret(why did it return that answer)
- Techniques researchers are using to add knowledge to LM:
- Add pretrained entity embeddings
- We need to know facts about the word are usually in terms of entities:

- We need to know facts about the word are usually in terms of entities:
- Add pretrained entity embeddings
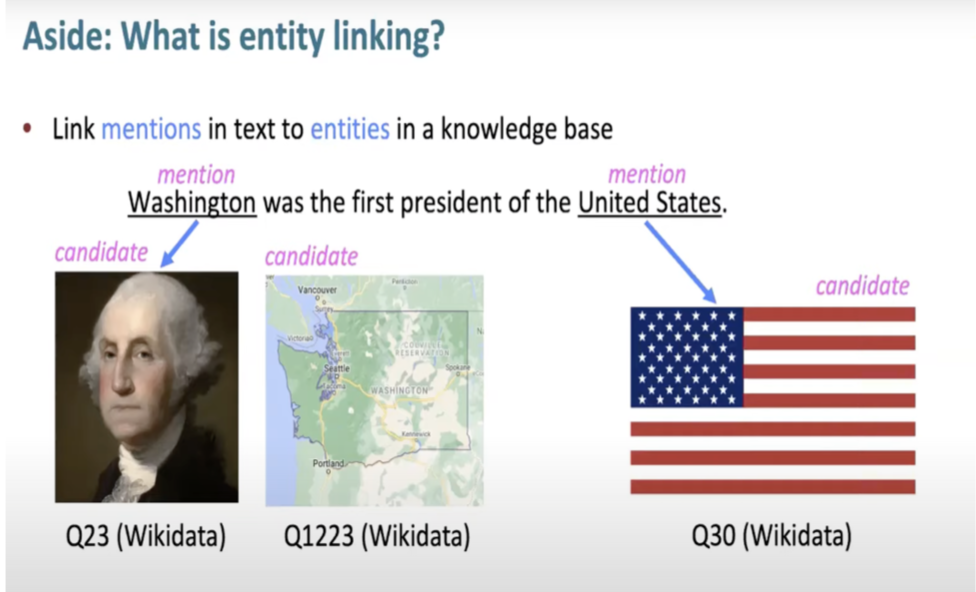
Entity Linking
- Link mentions in text to entities in a knowledge base
- Tells us which entity embeddings are relevant to the text
- They’re like word embeddings but for a knowledge base
- Knowledge graph embedding methods: TransE
- Wikipedia2Vec
- BLINK from facebook using a transformer
- How to incorporate when it’s from a different embedding space?
- Learn a fusion layer to combine context and entity information
- How to incorporate when it’s from a different embedding space?
ERNIE: Enhanced Language Representation with Informative Entities
- Pretrained entity embeddings
- Fusion layer
- Text encoder: multi layer bidirectional Transformer encoder(BERT) over the words in a sentence
- Knowledge encoder: stacked blocks composed of:
- Two multi headed attentions (MHAs) over entity embeddings and token embeddings
- A fusion layer to combine the output of the MHAs
- Output of fusion layer new word and entity embeddings
- Pretrained with 3 tasks:
- Masked language model and next sentence prediction (BERT tasks)
- Knowledge pretraining task: randomly mask token entity alignments and predict corresponding entity for a token from the entities in the sequence
- Point of the fusion layer is to find the correlation between word embeddings and entity embeddings in order to be able to correctly return the answer
KnowBert
- Key idea pretrain an integrated entity linker as an extension to BERT
- Learning entity learning may better encode knowledge
- Uses fusion layer to combine entity and context info and adds a knowledge pretraining tasks
KGLM
- LSTMs condition the language model on a knowledge graph
- LM predicts the next word by computing
- Now predict the next word using entity information, by computing
- Builds a “local” knowledge graph as you iterate over the sequence
- Local KG: subset of the full KG with only entities relevant to the sequence
- When should LM use knowledge graph vs predict next word
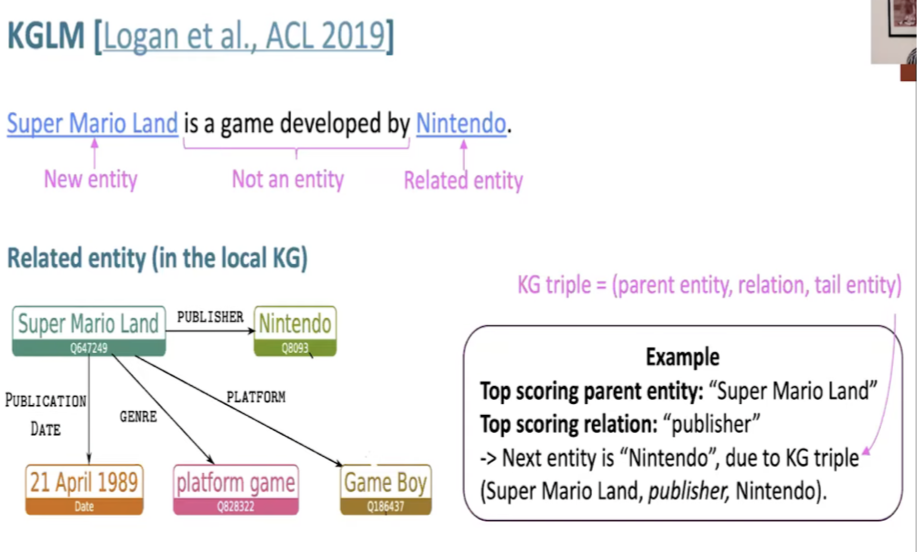
- Find top scoring parent and relation in the local KG using LSTM hidden state and pretrained entity and relation embeddings
- New entity:
- (not in local KG)
- Find top scoring entity in full KG using LSTM hidden state and pretrained entity embeddings
- KGLM outperforms GPT-2
- Nearest Neighbor Language Models (kNN-LM)
- Key idea: learning similarities between text sequence is easier than predicting the next word
- Store all representations of text sequences in a nearest neighbor datastore
Evaluating knowledge in LMs
- Language Model analysis: LAMA probe
- How much relational ( commonsense and factual) knowledge is already in off the shelf language models
- Without any additional training or fine tuning
- Limitations of the LAMA probe:
- Hard to understand why models perform well when they do
- BERT large may memorize co occurrence patterns rather than “understanding” the cloze statements
Citation
If you found our work useful, please cite it as:
@article{Chadha2021Distilled,
title = {Knowledge Graphs},
author = {Jain, Vinija and Chadha, Aman},
journal = {Distilled Notes for Stanford CS224n: Natural Language Processing with Deep Learning},
year = {2021},
note = {\url{https://aman.ai}}
}