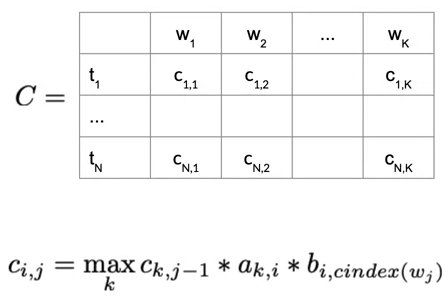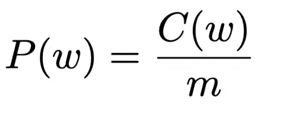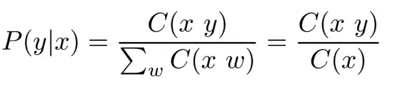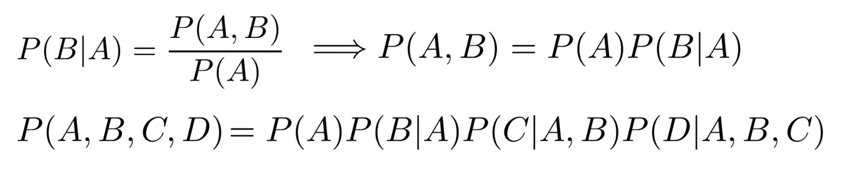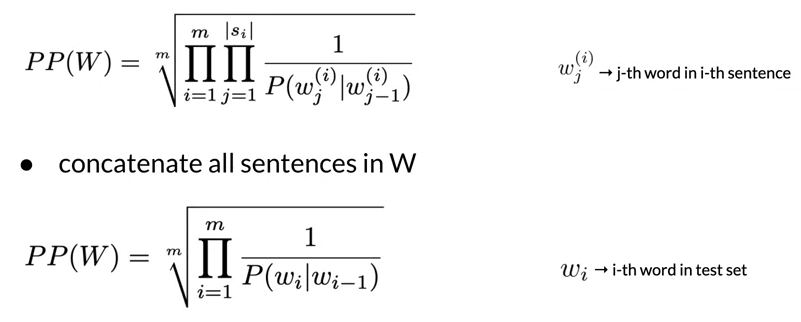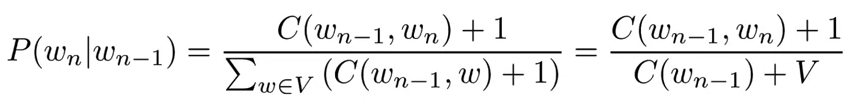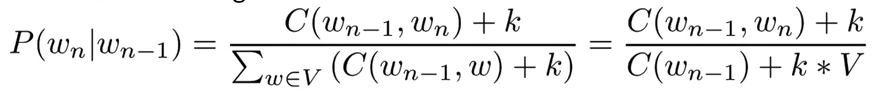Coursera-NLP • Natural Language Processing with Probabilistic Models
- Summary of Course 2
- Autocorrect and Dynamic Programming
- Autocomplete and Language Models
- Word embeddings with neural networks
Summary of Course 2
- In Course 2 of the Natural Language Processing Specialization, offered by deeplearning.ai, you will:
a) Learn about probabilistic models which lend themselves to the task of estimating the probability of the next word being the word the versus another word in the vocbulary, given the previous word (or a set of initial words).
Create a simple auto-correct algorithm using minimum edit distance and dynamic programming, Apply the Viterbi Algorithm for part-of-speech (POS) tagging, which is important for computational linguistics, Write a better auto-complete algorithm using an N-gram language model, and Write your own Word2Vec model that uses a neural network to compute word embeddings using a continuous bag-of-words model.
Please make sure that you’re comfortable programming in Python and have a basic knowledge of machine learning, matrix multiplications, and conditional probability.
By the end of this Specialization, you will have designed NLP applications that perform question-answering and sentiment analysis, created tools to translate languages and summarize text, and even built a chatbot!
This Specialization is designed and taught by two experts in NLP, machine learning, and deep learning. Younes Bensouda Mourri is an Instructor of AI at Stanford University who also helped build the Deep Learning Specialization. Łukasz Kaiser is a Staff Research Scientist at Google Brain and the co-author of Tensorflow, the Tensor2Tensor and Trax libraries, and the Transformer paper.
-
In Course 3, you will: a) Build upon the foundations in course 1 and 2, and explore sequence models.
-
In Course 4, you will: a) Learn about attention models which form the backbone of today’s models. Combine attention and parallel computing to come up with state-to-the-art (SoTA) NLP models that enable neural machine translation, summarization, question answering and chatbots. These models have high impact in the industry and could be used, for example, to automate call centers or businesses can use them to make sense of large volumes of data.
Autocorrect and Dynamic Programming
Autocorrect
- Autocorrect is an application that changes misspelled words into the correct ones.
- Example: Happy birthday deah friend! ==> dear
- How it works:
- Identify a misspelled word
- Find strings n edit distance away
- Filter candidates
- Calculate word probabilities
Building the model
- Identify a misspelled word
- If word not in vocabulary then its misspedlled
- Find strings n edit distance away
- Edit: an operation performed on a string to change it
- how many operations away one string is from another
- Insert (add a letter)
- Add a letter to a string at any position: to ==> top,two,…
- Delete (remove a letter)
- Rmove a letter from a string : hat ==> ha, at, ht
- Switch (swap 2 adjacent letters)
- Exmaple: eta=> eat,tea
- Replace (change 1 letter to another)
- Example: jaw ==> jar,paw,saw,…
- Insert (add a letter)
- how many operations away one string is from another
- Edit: an operation performed on a string to change it
- By combining the 4 edit operations, we get list of all possible strings that are n edit.
- Filter candidates:
- From the list from step 2, consider only real and correct spelled word
- if the edit word not in vocabualry ==> remove it from list of candidates
- Calculate word probabilities: the word candidate is the one with the highest probability
- a word probablity in a corpus is: number of times the word appears divided by the total number of words.

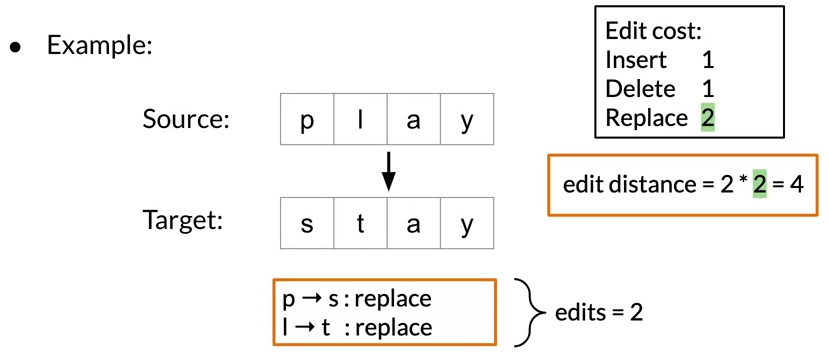
Minimum edit distance
- a word probablity in a corpus is: number of times the word appears divided by the total number of words.
- Evaluate the similarity between 2 strings
- Minimum number of edits needed to transform 1 string into another
- the algorithm try to minimize the edit cost
- Applications:
- Spelling correction
- document similarity
- machine translation
- DNA sequencing
- etc
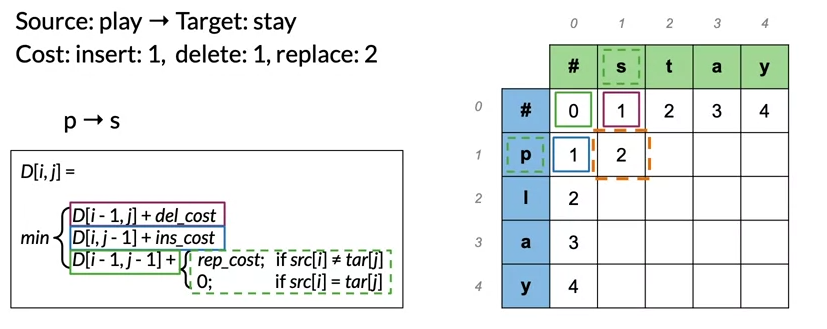
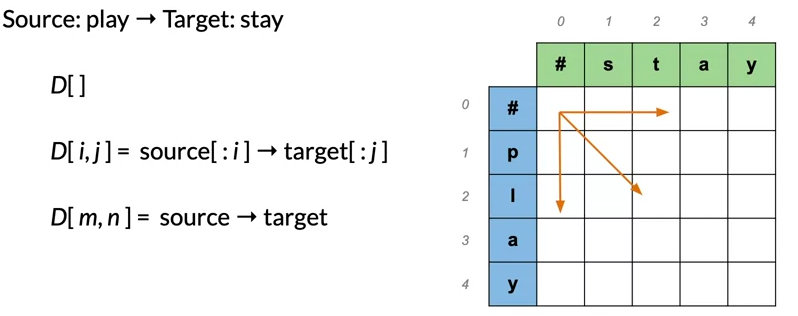
Minimum edit distance algorithm
- The source word layed on the column
- The target word layed on the row
- Empty string at the start of each word at (0,0)
- D[i,j] is the minimum editing distance between the beginning of the source word to index i and the beginning of the target word to index j
- To fillout the rest of the table we can use this formulaic approach:
Part of Speech Tagging and Hidden Markov Models
Part of Speech Tagging
- Part-of-speech refers to the category of words or the lexical terms in the language
- tags can be: Noun, Verb, adjective, preposition, adverb,…
- Example for the sentence: why not learn something ?
- Applications:
- Named entities
- Co-reference resolution
- Speech recognition
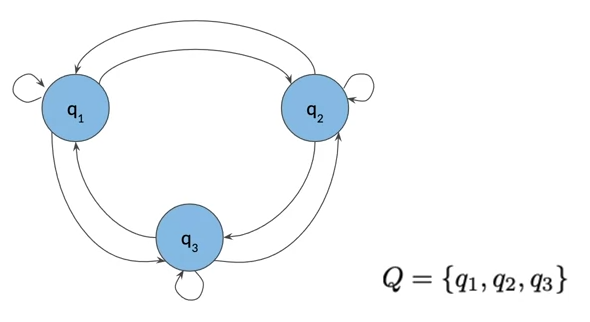
Markov Chains
- Markov chain can be depicted as a directed graph
- a graph is a kind of data structure that is visually represented as a set of circles connected by lines.
- The circles of the graph represents states of our model
- The arraows from state s1 to s2 represents the transition probabilities, the likelihood to move from s1 to s2


Markov Chains and POS Tags
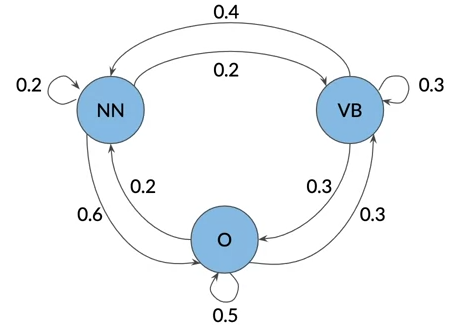
- Think about a sentence as a sequence of words with associated parts of speech tags
- we can represent that sequence with a graph
- where the parts of speech tags are events that can occur depicted by the states of the model graph.
- the weights on the arrows between the states define the probability of going from one state to another
- The probability of the next event only depends on the current events
- The model graph can be represented as a Transition matrix with dimension n+1 by n
- when no previous state, we introduce an initial state π.
- The sum of all transition from a state should always be 1.
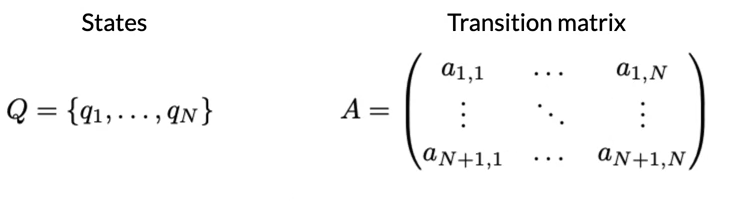
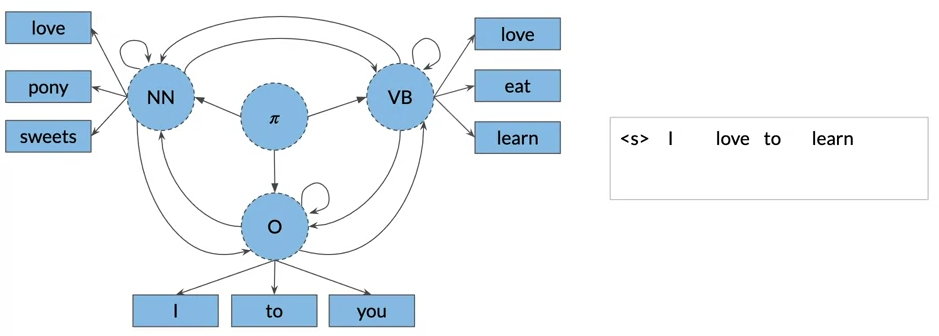
Hidden Markov Chains models
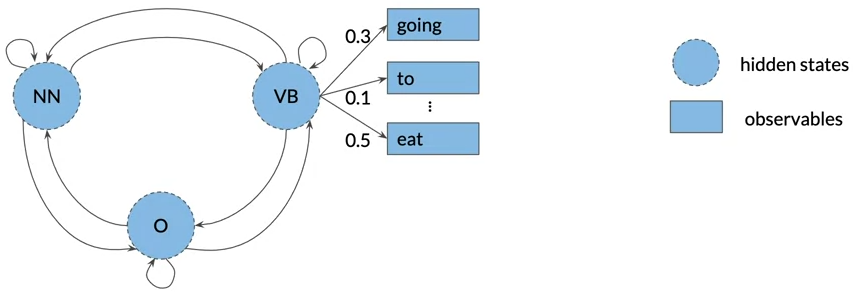
- The hidden Markov model implies that states are hidden or not directly observable
- The hidden Markov model have a transition probability matrix A of dimensions (N+1,N) where N is number of hidden states
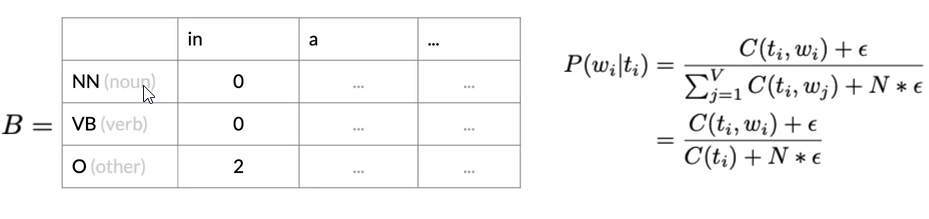
- The hidden Markov model have emission probabilities matrix B describe the transition from the hidden states to the observables(the words of your corpus)
- the row sum of emission probabity for a hidden state is 1
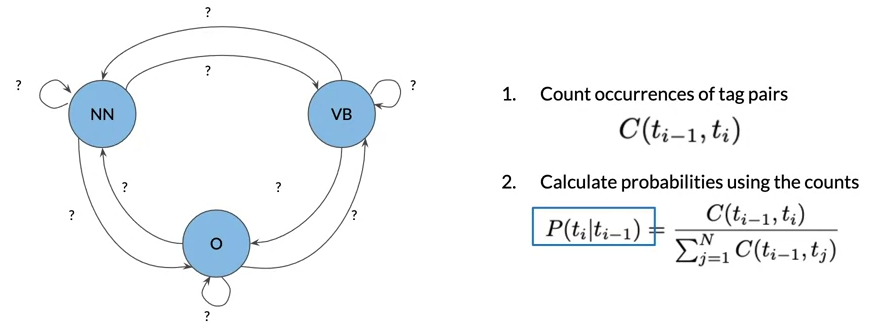
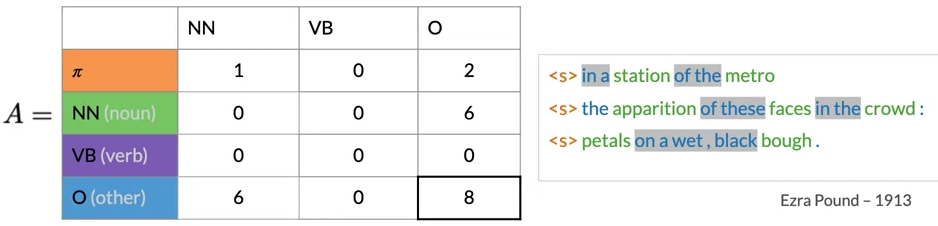
The Transition Matrix
- Transition matrix holds all the transition probabilities between states of the Markov model
- C(ti-1,ti) count all occurrences of tag pairs in your training corpus
- C(ti-1,tj) count all occurrences of tag ti-1
- to avoid division by zero and lot of entries in the transition matrix are zero, we apply smoothing to the probability formula
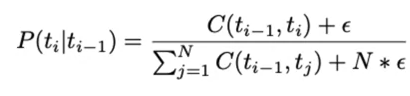
The Emission Matrix
- Count the co-occurrences of a part of speech tag with a specific word.
The Viterbi Algorithm
- The Viterbi algorithm is actually a graph algorithm
- The goal is to to find the sequence of hidden states or parts of speech tags that have the highest probability for a sequence
- The algorithm can be split into three main steps: the initialization step, the forward pass, and the backward pass.
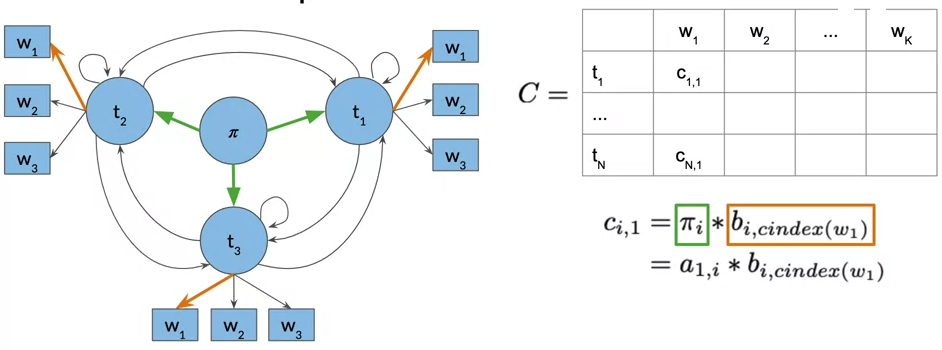
- Given your transition and emission probabilities, we first populates and then use the auxiliary matrices C and D
- matrix C holds the intermediate optimal probabilities
- matrix D holds the indices of the visited states as we are traversing the model graph to find the most likely sequence of parts of speech tags for the given sequence of words, W1 all the way to Wk.
- C and D matrix have n rows (number of parts of speech tags) and k comlumns (number of words in the given sequence)
Initialization
- The initialization of matrix C tell the probability of every word belongs to a certain part of speech.
- in D matrix, we store the labels that represent the different states we are traversing when finding the most likely sequence of parts of speech tags for the given sequence of words W1 all the way to Wk.
Forward Pass
- For the C matrix, the entries are calculated by this formula:
- For matrix D, save the k, which maximizes the entry in ci,j.
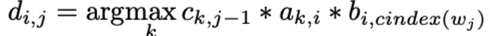
Backward Pass
- The backward pass help retrieve the most likely sequence of parts of speech tags for your given sequence of words.
- First calculate the index of the entry, Ci,K, with the highest probability in the last column of C
- represents the last hidden state we traversed when we observe the word wi
- Use this index to traverse back through the matrix D to reconstruct the sequence of parts of speech tags
- multiply many very small numbers like probabilities leads to numerical issues
- Use log probabilities instead where numbers are summed instead of multiplied.
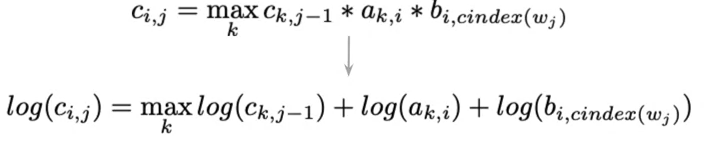
Autocomplete and Language Models
N-Grams
- A language model is a tool that’s calculates the probabilities of sentences.
- Language models can estimate the probability of an upcoming word given a history of previous words.
- apply language models to autocomplete a given sentence then it outputs a suggestions to complete the sentence
- Applications:
- Speech recognition
- Spelling correction
- Augmentativce communication
N-grams and Probabilities
- N-gram is a sequence of words. N-grams can also be characters or other elements.

- Sequence notation:
- m is the length of a text corpus
- Wij refers to the sequence of words from index i to j from the text corpus
- Uni-gram probability
- Bi-gram probability
- N-gram probability
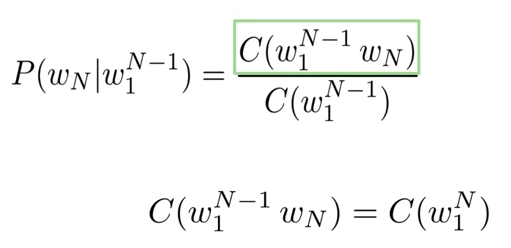
Sequence Probabilities
- giving a sentence the Teacher drinks tea, the sentence probablity can be represented as based on conditional probability and chain rule:
- this direct approach to sequence probability has its limitations, longer parts of your sentence are very unlikely to appear in the training corpus.
-
P(tea the teacher drinks) - Since neither of them is likely to exist in the training corpus their counts are 0.
- The formula for the probability of the entire sentence can’t give a probability estimate in this situation.
-
- Approximation of sequence probability
- Markov assumption: only last N words matter
-
Bigram P(wn w1n-1) ≈ P(wn wn-1) -
Ngram P(wn w1n-1) ≈ P(wn wn-N+1n-1) - Entire sentence modeled with Bigram:
Starting and Ending Sentences
- Start of sentence symbol:
- End of sentence symbol: </s>
The N-gram Language Model
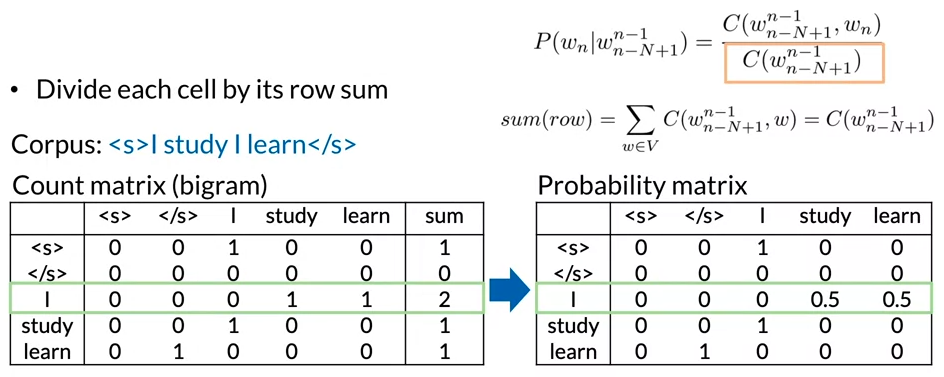
- The count matrix captures the number of occurrences of relative n-grams
- Transform the count matrix into a probability matrix that contains information about the conditional probability of the n-grams.
- Relate the probability matrix to the language model.
- Multiplying many probabilities brings the risk of numerical underflow,use the logarithm of a product istead to write the product of terms as the sum of other terms.
Language Model evaluation
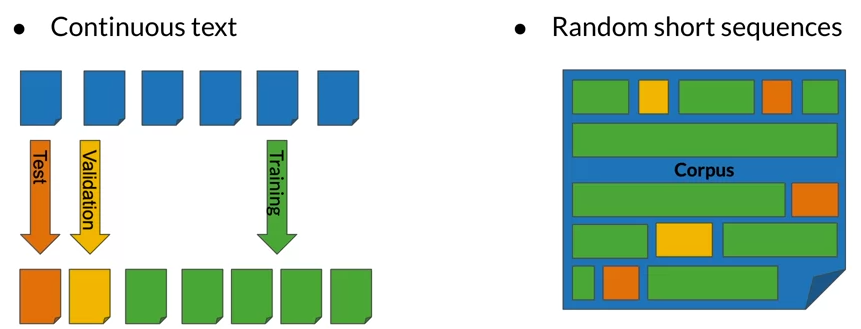
- In order to evaluate a Language model, split the text corpus into train (80%), validation (10%) and Test (10%) set.
- Split methods can be: continus text or Random short sequences
- Evaluate the language models using the perplexity metric

- The smaller the perplexity, the better the model
- Character level models PP is lower than word-based models PP
- Perplexity for bigram models
- Log perplexity
Out of Vocabulary Words
- Unknown words are words not find the vocabuary.
- model out of vocabulary words by a special word UNK.
- any word in the corpus not in the vocabulary will be replaced by UNK
Smoothing
- When we train n-gram on a limited corpus, the probabilities of some words may be skewed.
- This appear when N-grams made of known words still might be missing in the training corpus
- Their count can not be used for probability estimation
- Laplacian smoothing or Add-one smoothing
- Add-K smoothing
- BackOff:
- If n-gram information is missing, we use N minus 1 gram.
- If that’s also missing, we would use N minus 2 gram and so on until we find non-zero probability
- This method distorts the probability distribution. Especially for smaller corporal
- Some probability needs to be discounted from higher level n-gram to use it for lower-level n-gram, e.g. Katz backoff
- In very large web-scale corpuses, a method called stupid backoff has been effective.
- With stupid backoff, no probability discounting is applied
- If the higher order n-gram probability is missing, the lower-order n-gram probability is used multiplied by a constant 0.4
-
P(chocolate Jhon drinks) = 0.4 x P(chocolate drinks)
- Linear interpolation of all orders of n-gram
- Combine the weighted probability of the n-gram, N minus 1 gram down to unigrams.
Word embeddings with neural networks
Basic Word Representations
- The simplest way to represent words as numbers is for a given vocabulary to assign a unique integer to each word
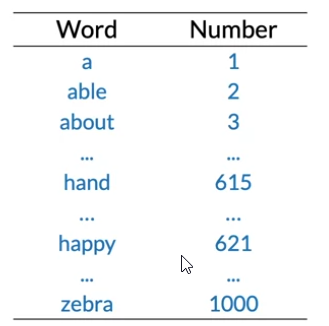
- Although it’s simple representation, it has little sementic sense
- One-Hot Vector representation
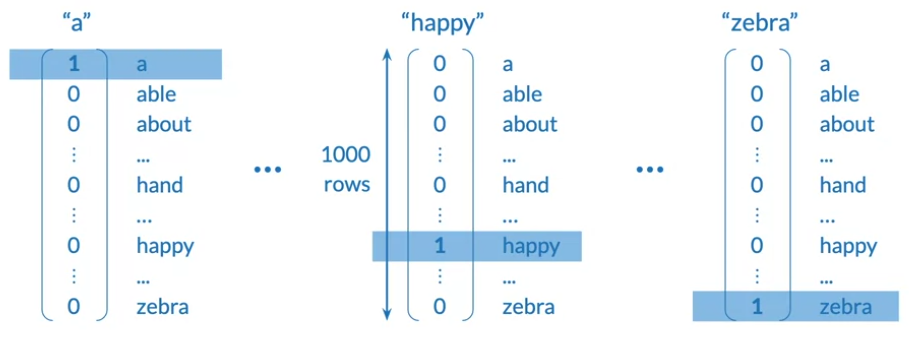
- Although it’s simple representation and not implied in ordering, but can be huge for computation and doesn’t embed meaning
Word Embeddings
- Word embeddings are vectors that’s carrying meaning with relatively low dimension
- To create a word embeddings you need a corpus of text and an embedding method
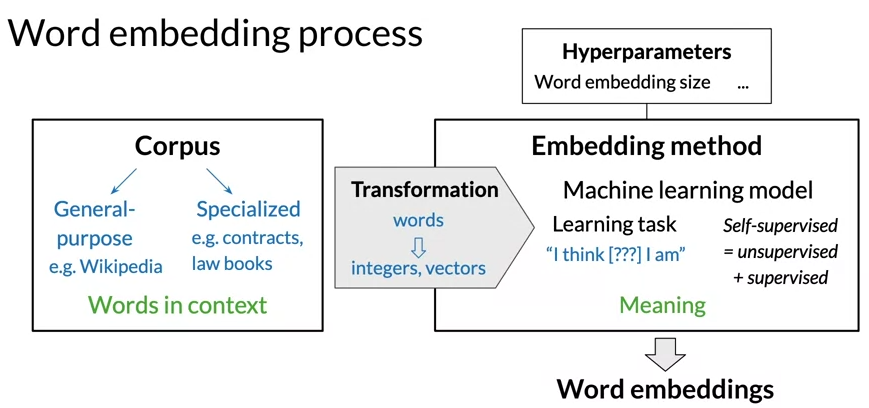
Word Embedding Methods
- Word2vec: which initially popularized the use of machine learning, to generate word embeddings
- Word2vec uses a shallow neural network to learn word embeddings
- It proposes two model architectures,
- Continuous bag of words(CBOW) which predict the missing word just giving the surround word
- Countinuous skip-gram/ skip-gram with negative sampling(SGNS) which does the reverse of the CBOW method, SGNS learns to predict the word surrounding a given input word
- GloVe: involves factorizing the logarithm of the corpuses word co-occurrence matrix, similarly to the counter matrix
- fastText: based on the skip-gram model and takes into account the structure of words by representing words as an n-gram of characters.
- This enables the model to support previously unseen words, known as outer vocabulary words(OOV), by inferring their embedding from the sequence of characters they are made of, and the corresponding sequences that it was initially trained on.
- Word embedding vectors can be averaged together to make vector representations of phrases and sentences.
- Other examples of advanced models that generate word embeddings are: BERT,GPT-2,ELMo
Continuous Bag-of-Words Model
- CBOW is ML-based embedding methods that try to predict a missing word based on the surrounding words.
- The rationale is that if two unique words are both frequently surrounded by a similar sets of words when used in various sentences => those two words tend to be related semantically.
- To create training data for the prediction task, we need set of example of context words and center words
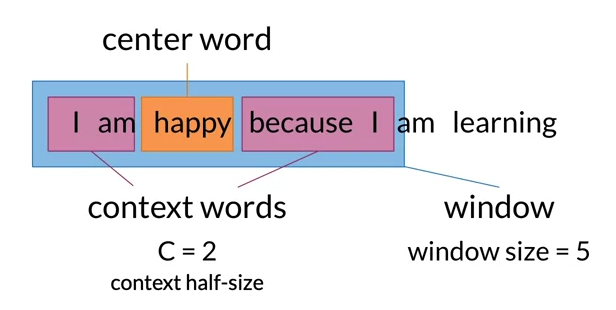
- by sliding the window, you creating the next traing example and the target center word
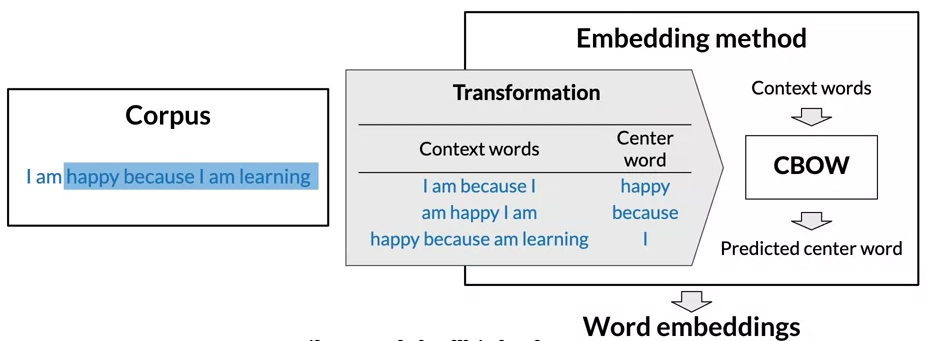
Cleaning and Tokenization
- We should consider the words of your corpus as case insensitive, The==THE==the
- Punctuation: represents ? . , ! and other characters as a single special word of the vocabulary
- Numbers: if numbers not caring meaning in your use-case, we can drop them or keep them (its possible to replace them with special token
) - Special characters: math/ currency symbols, paragraph signs
- Special words: emojis, hashtags
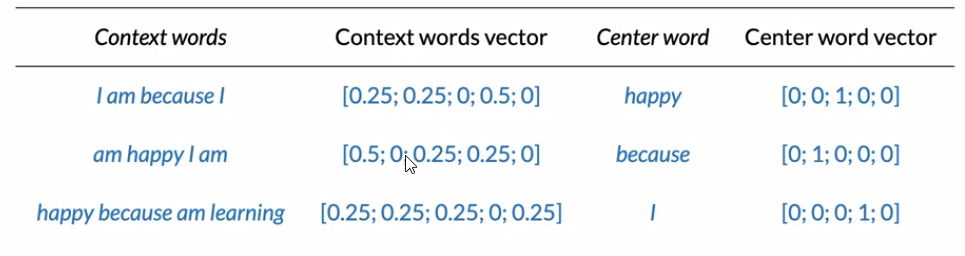
Transforming Words into Vectors
- This done by transforming centeral and context word into one-hot vectors
- Final prepared training set is:
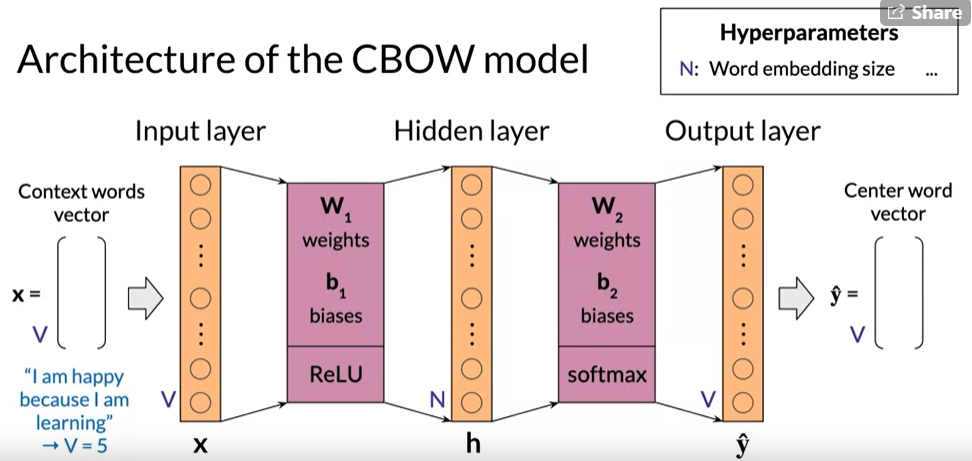
Architecture of the CBOW Model
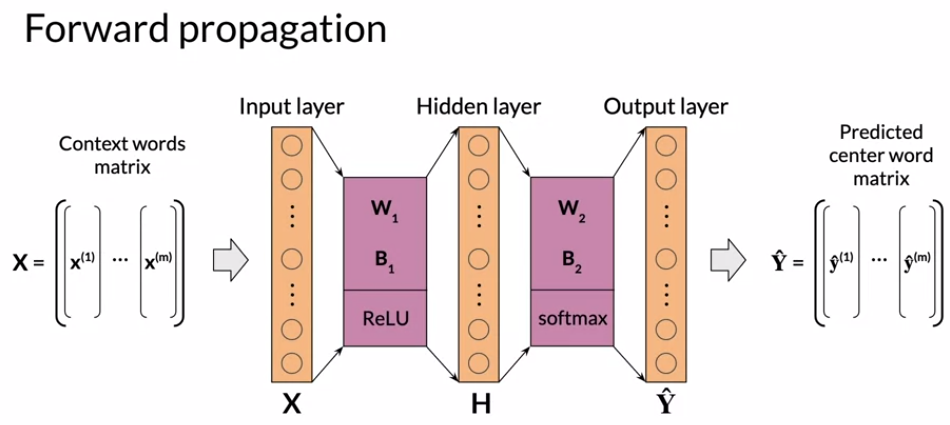
- The Continuous Bag of Words model is based on the shallow dense neural network with an input layer, a single hidden layer, and output layer.
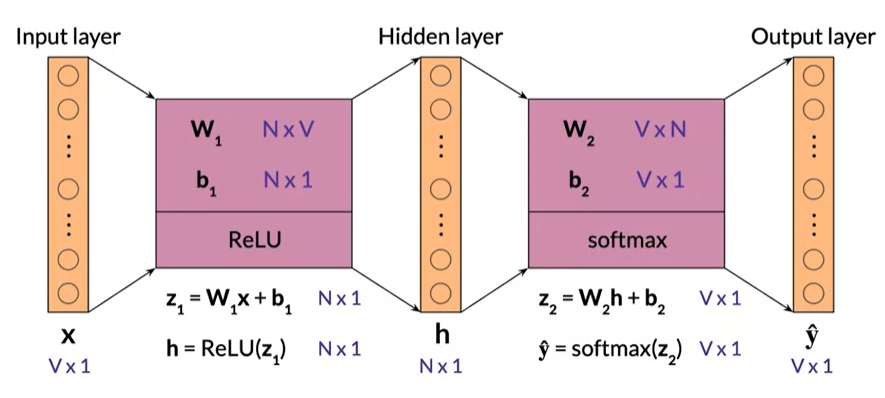
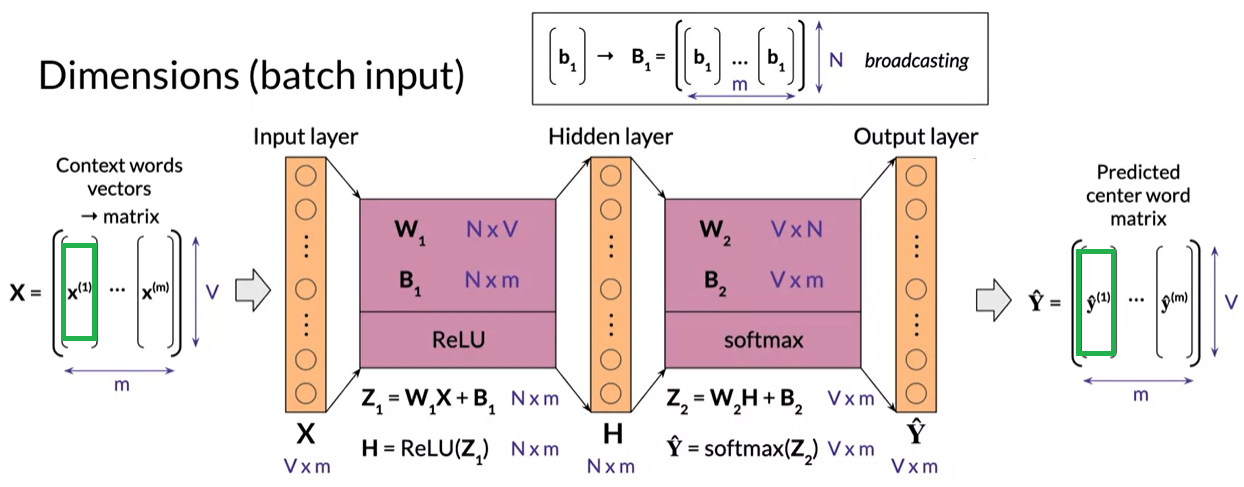
CBOW Model Dimensions
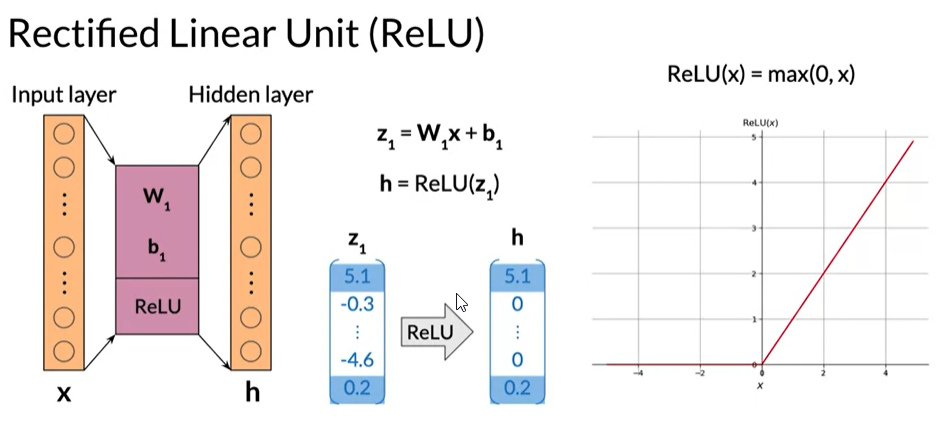
Activation Functions
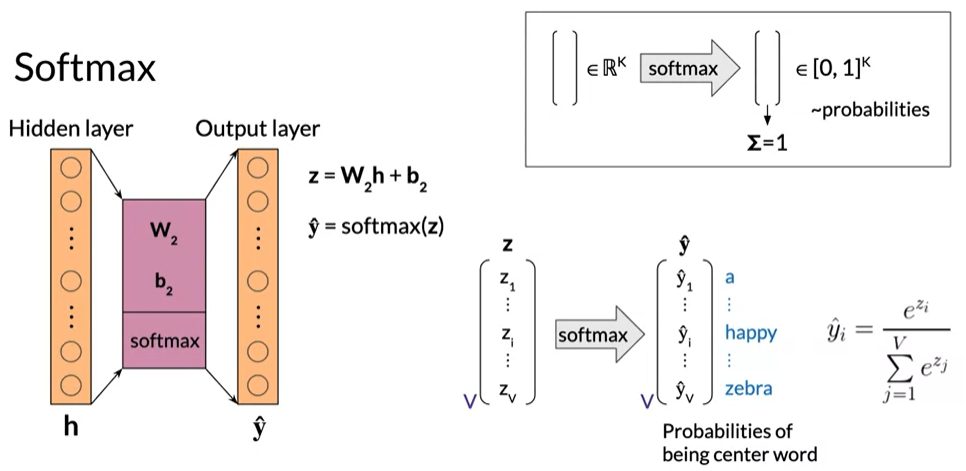
Cost Functions
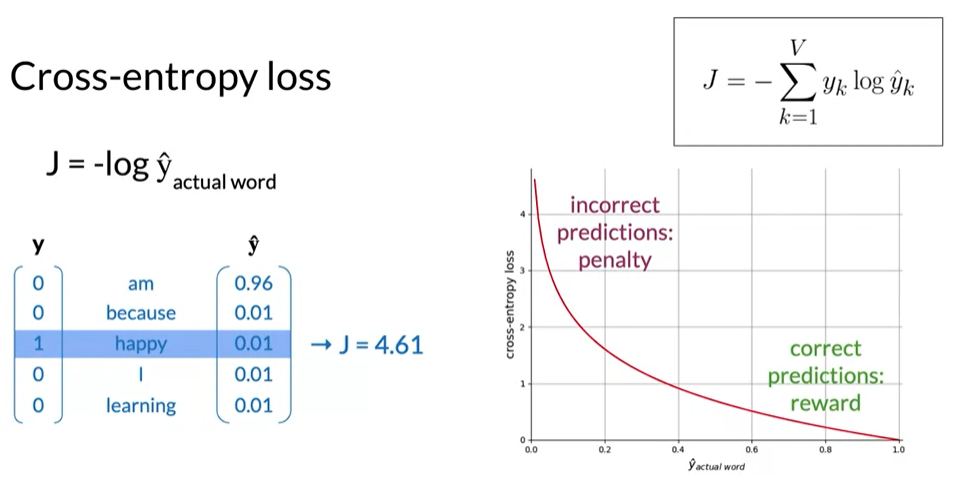
- The objective of the learning process is to find the parameters that minimize the loss given the training data sets using the cross-entropy loss
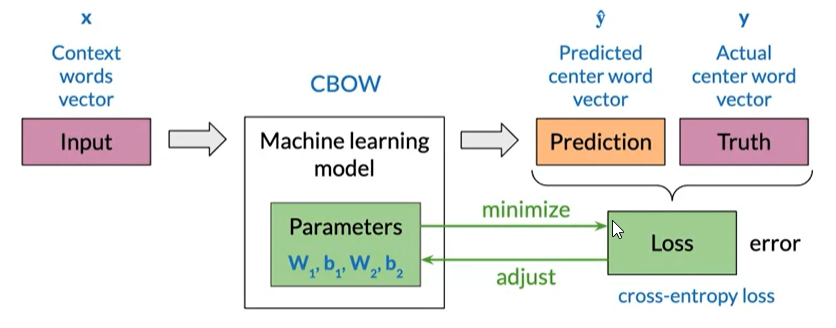
Forward Propagation
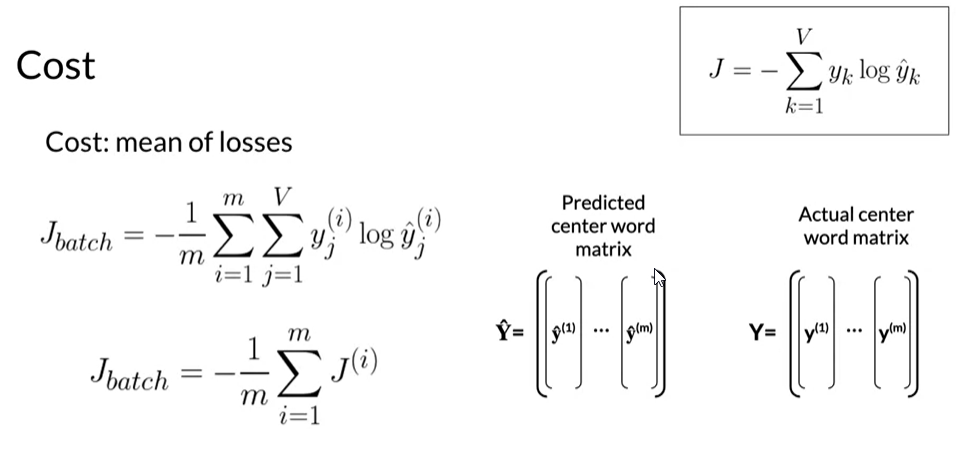
Backpropagation and Gradient Descent
- Backpropagation calculate the partial derivatives of cost with respect to weights and biases
- Gradient descent update weights and biases

Extracting Word Embedding Vectors
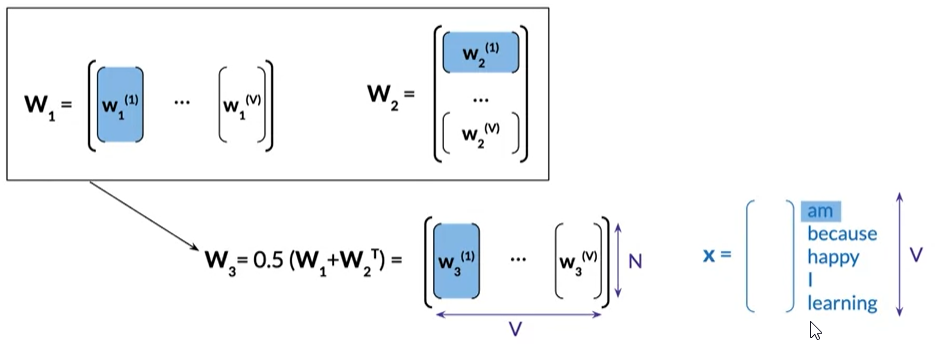
- Afterwe have trained the neural network, we can extract three alternative word embedding representations
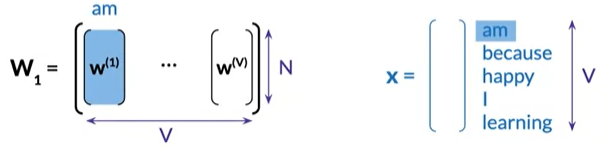
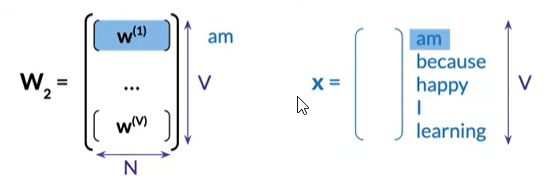
- consider each column of W_1 as the column vector embedding vector of a word of the vocabulary
- use each row of W_2 as the word embedding row vector for the corresponding word.
- average W_1 and the transpose of W_2 to obtain W_3, a new n by v matrix.
Evaluating Word Embeddings
Intrinsic Evaluation
- consider each column of W_1 as the column vector embedding vector of a word of the vocabulary
- Intrinsic evaluation methods assess how well the word embeddings inherently capture the semantic(meaning) or syntactic(grammar) relationships between the words.
- Test on semantic analogies
- Using a clustering algorithm to group similar word embedding vectors, and determining of the cluster’s capture related words
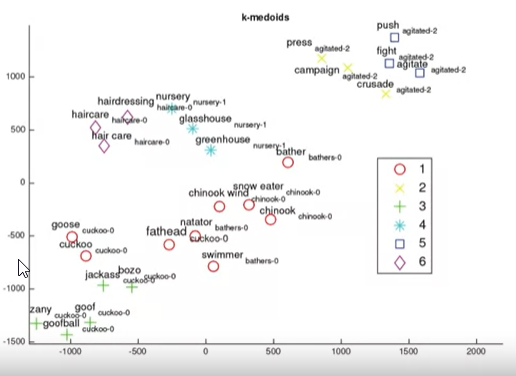
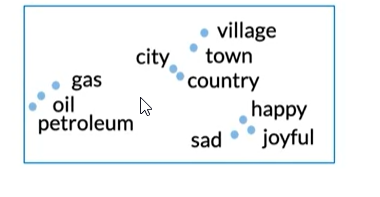
Extrinsic Evaluation
- Test the word embeddings to perform an external task, Named Entity recognition, POS tagging
- Evaluate this classifier on the test set with some selected evaluation metric, such as accuracy or the F1 score.
- The evaluation will be more time-consuming than an intrinsic evaluation and more difficult to troubleshoot.