Coursera-NLP • Machine Translation using Locality Sensitive Hashing
- Overview
- Background: Frobenius norm
- Machine translation: Transforming word vectors
- Key takeaways
- Citation
Overview
- In Vector Spaces, we learned about:
- Word vectors and how they capture relative meanings of words.
- Representing a document as a vector by adding up the vector representations for its constituent words.
- In this topic, we’ll build a simple machine translation system that makes use of locality sensitive hashing to improve the performance of nearest neighbor search.
Background: Frobenius norm
- The Frobenius norm measures the magnitude of a matrix. It is a generalization of the vector norm for matrices.
- Formally, the Frobenius norm of a matrix \(A\) is given by,
- Interpreting the above equation, the Frobenius norm can be obtained by taking the elements in the matrix, squaring them, adding them up and taking the square root of the result.
- Let’s take an example. Consider a matrix A:
- To calculate its norm,
- Programmatically, here’s the Frobenius norm in code:
import numpy as np
# Start with a matrix A
A = np.array([[2, 2], [2, 2]])
# Use np.square() to square all the elements
A_squared = np.square(A)
print(A_squared) # Prints [[4, 4],
# [4 ,4]]
# Use np.sum(), then np.sqrt() to get 4.
A_Frobenius = np.sqrt(np.sum(A_squared))
print(A_Frobenius) # Prints 4.0
Machine translation: Transforming word vectors
- To build our first basic translation program, let’s use word vectors to to align words in two different languages. Later, we’ll explore locality sensitive hashing to speed things up!
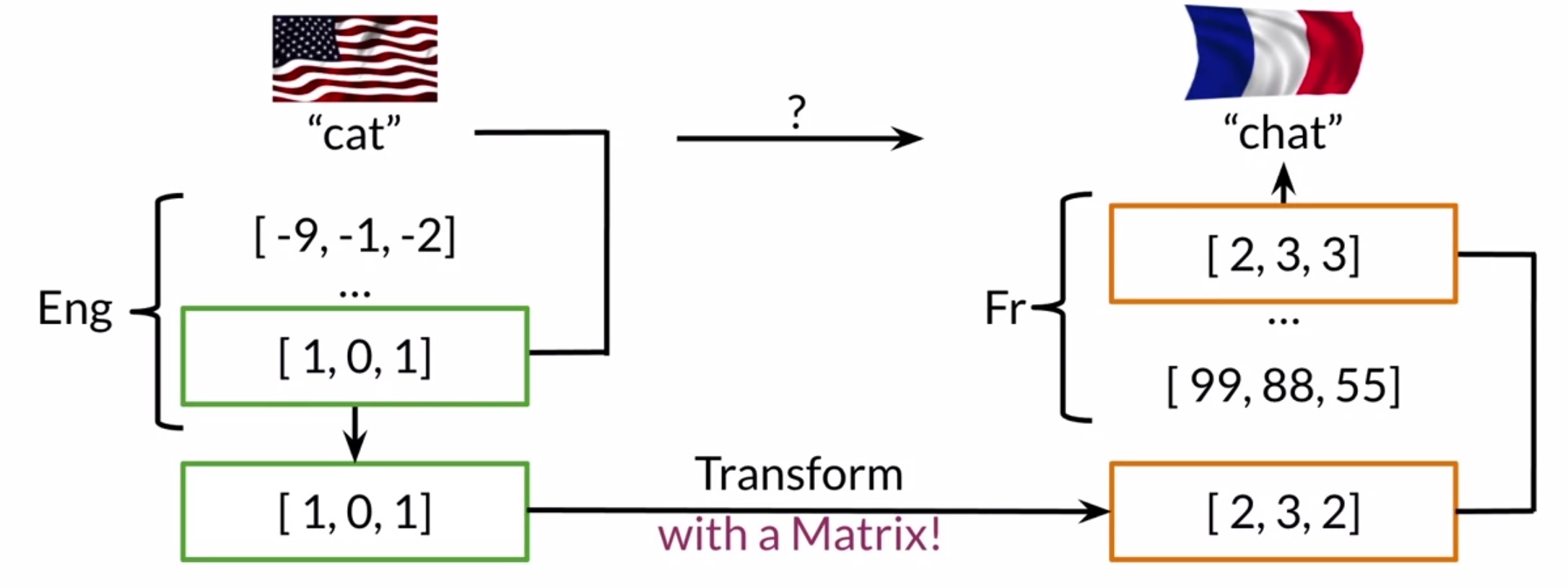
- To get an overview of machine translation, let’s starting with an example of English \(\rightarrow\) French translation. In order to translate an English word to a French word, a naive way would be to generate an extensive list of English words and their associated French word.
- For a human to accomplish this task, you would need to find someone who knows both languages to start making a list.
- For a machine to accomplish this task, you’ll need to perform the following steps:
- Calculate word embeddings for words in both your English and French vocabulary.
- Retrieve the word embedding of a particular English word such as cat, and find a way to transform the English word embedding into a word embedding that has a meaning in the French word vector space (more on this below).
- Take the transformed word vector and search for word vectors in the French word vector space that are similar to it. These similar words are candidates for your translation.
- If your machine does a good job, it may find the word chat, which is the French word for cats.
- Putting these ideas together with code:
import numpy as np
R = np.array([[2, 0], [0, -2]]) # Define the matrix R
x = np.array([[1, 1]]) # Define the vector x
prod = np.dot(x, R) # Multiply x by R using np.dot ((1 x 2) x (2 x 2)) to yield a two dimensional vector.
print(prod) # Prints [[2, -2]]
- Let’s figure out how to find a transformation matrix \(R\) that can transform English word vectors into corresponding French word vectors. We’ll start with a randomly initialized matrix \(R\) and evaluate it by using it translate English vectors, denoted by matrix \(X\), and compare that to the actual French word vectors, denoted by matrix \(Y\).
- In order for this to work,
- Get a subset of English words and their French equivalents.
- Get their respective word vectors.
- Stack the word vectors in their respective matrices \(X\) and \(Y\).
- Note that the key here is to make sure the English and French word vectors are aligned. For e.g., if the first row of matrix \(X\) contains the word cat, the first row of the matrix \(Y\) should contain the French word for cat, which is chat.
- Keep in mind that the broader goal here is to use a subset of these words to find your transformation matrix \(R\) which can be used to translate words that are not part of your original training set. We thus only need to train on a subset of the English-French vocabulary and not the entire vocabulary.
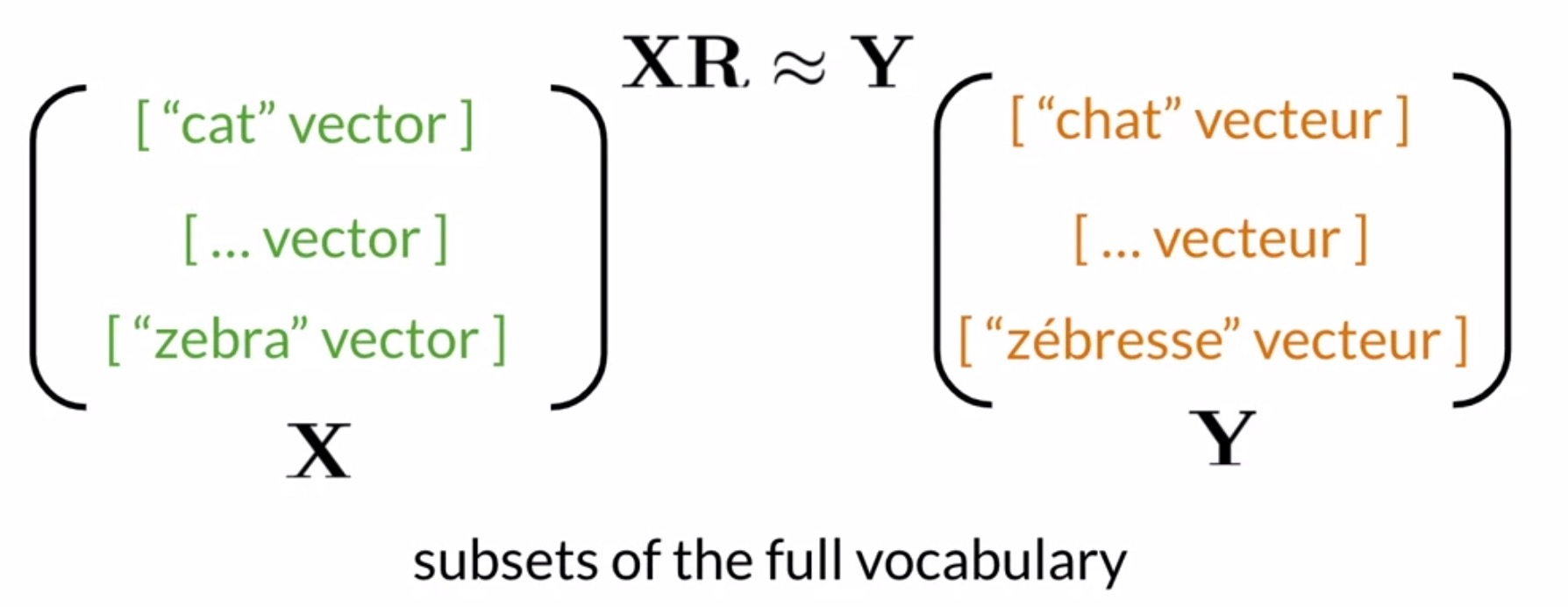
- Given that our objective is to make the transformation of \(X\) as similar to \(Y\) as possible, i.e., \(XR \approx Y\), we would need to minimize the distance between \(XR\) and \(Y\) to get the optimal version of \(R\).
- Next, to find a good matrix \(R\) we simply compare the translation \(XR\) with the actual French word embeddings \(Y\). Comparison is essentially subtraction. We thus take \(XR\) and subtract the \(Y\) matrix. Taking the Frobenius norm of this quantity gives us the loss, interpreted as the measure of our unhappiness with the current transformation matrix \(R\).
- As an example of calculating the Frobenius norm, let’s say that the expression \(XR-Y\) yields a matrix.
- Now, assume for the sake of this example that there are only two words in our vocabulary, which represents the number of rows in our matrix \(R\) and the word embeddings have 2 dimensions, which represent the number of columns in the matrix. Thus, matrices \(X\), \(R\), \(Y\) and \(A\) are matrices of dimensions \(2 \times 2\).
- Now, if A is:
- The Frobenius norm of \(A\) is \(\left||A|\right|_{F}=\sqrt{1^{2}+1^{2}+1^{2}+1^{2}} = 2\).
- Starting with a random matrix \(R\), we can iteratively improve this matrix \(R\) using gradient descent:
- Compute the gradient by taking the derivative of this loss function with respect to the matrix \(R\).
- Update the matrix \(R\) by subtracting the gradient weighted by the learning rate \(\alpha\).
- Either pick a fixed number of times to go through the loop or check the loss at each iteration and break out of the loop when the loss falls between a certain threshold.
- Algorithmically,
- Initialize \(R\) randomly, or with zeros.
- In a loop:
- Note that in practice, it’s easier to minimize the square of the Frobenius norm. In other words, we can cancel out the square root in the Frobenius norm formula by taking the square.
- The reason behind using the square of the Frobenius norm is that its easier to take the derivative of the squared expression rather than dealing with the square root within the Frobenius norm (explained below).
- Re-visiting our example from earlier,
- Next, let’s calculate the gradient of the loss function.
- As seen earlier, the loss is defined as the square of the Frobenius norm. Starting with our loss equation,
-
The gradient is the derivative of the loss with respect to the matrix \(R\):
\[g=\frac{d}{d R} Loss=\frac{2}{m}\left(X^{T}(XR-Y)\right)\\\]- where the scalar \(m\) is the number of rows or words in the subset that we’re using for training.
- Based on the above gradient expression, it is easy to understand why the derivative of the squared Frobenius norm is relatively easy to calculate compared to that of the Frobenius norm.
- Key takeaways
- With one trainable matrix you can learn to align word vectors from one language to another and thus carry out machine translation.
K-nearest neighbors
- A key operation needed to find a matching word in the previous video was finding the K-nearest neighbors of a vector.
- We will focus on this operation in the next few videos as it’s a basic building block for many NLP techniques.
- Notice that it transformed word vector after the transformation of its embedding through an \(R\) matrix would be in the French word vector space. But it is not going to be necessarily identical to any of the word vectors in the French word vector space. You need to search through the actual French word vectors to find a French word that is similar to the one that you created from the transformation. You may find words such as salut or bonjour, which you can return as the French translation of the word hello. So the question is, how do you find similar word vectors? To understand how to find similar word vectors, let’s look at a related question. How do you find your friends who are living nearby? Let’s pretend that you are visiting San Francisco in the United States and you’re visiting your dear friend Andrew. You also want to visit your other friends over the weekend, preferably those who live nearby. One way to do this is to go through your address book and for each friend get their address, calculate how far they are from San Francisco. So one friend is in Shanghai, the other friend is in Bangalore, and another friend is in Los Angeles. You can sort your friends by their distances to San Francisco, then rank them by how close they are. Notice that if you have a lot of friends, which I’m sure you do, this is a very time intensive process. Is there a more efficient way to do this? Notice that two of these friends live in another continent, while the third friend lives in the United States. Could you have just searched for a subset of friends who live in the United States? You might have realized that it may not have been necessary to go through all of your friends in your address in order to find the ones closest to you. You might have imagined if you somehow could filter on which friends were all in a general region, such as North America, then you could just search within that sub group of friends. If there is a way to slice up the geographic space into regions, you could search just within those regions. When you think about organizing subsets of a dataset efficiently, you may think about placing your data into buckets. If you think about buckets, then you’ll definitely want to think about hash tables. Hash tables are useful tools for any kind of work involving data, and you’ll learn about hash tables next. In this video, I showed you how using K-nearest neighbors you could translate a word even if it’s transformation doesn’t exactly match the word embedding in the desired language. And I introduced you to hash tables, a useful data structure that you will learn about in the next video.
- Key takeaways
- To translate from \(X\) to \(Y\) using the \(R\) matrix, you may find that \(XR\) doesn’t correspond to any specific vector in \(Y\).
- KNN can search for the \(K\) nearest neighbors from the computed vector \(XR\).
- Thus searching in the whole space can be slow, using a hash tables can minimize your search space.
- Hash tables may omit some neighbors that are close to your computed vector.
Hash tables and hash functions
- A hush function maps an object to a bucket in a hash table

- A simple hash function : Hash Value = vector % number of buckets

- This function does not store similar objects in the same bucket ⇒ Locality sensitive hashing
Locality Sensitive Hashing
- Separate the space using hyperplanes

- For each vector v compute its scalar product sign with a normal vector on a hyperplane hi.
- the product sign determines on which side the vector is.
- If the dot product is positive the hi = 1, else hi=0

- the hash value is:

Approximate nearest neighbors
- Subdivide the space using multiple sets of random planes

- Each subdivision will give (probably) different vectors in the same bucket of the computed vector
- Those different vectors (from multiple subdivisions) are good candidates to be the k nearest neighbors

- This Approximate nearest neighbors is not perfect but it is much faster than naive search
Key takeaways
- Learnings from this topic:
- Implement machine translation to translate the English word hello to the French word bonjour.
- Implement document search. For e.g., given a sentence, “Can I get a refund?”, you can search for similar sentences such as, “What’s your return policy?” or “May I get my money back?”
- Both the tasks of machine translation and document search have common underlying concepts:
- Transform a word to its vector representation.
- k-nearest neighbors, which is a way of searching for similar items.
- Hash tables which help you distribute your word vectors into subsets by dividing the vector space into regions.
- Locality sensitive hashing, which helps you perform approximate k-nearest neighbors, an efficient way of searching for similar word vectors.
- To implement machine translation and document search, the task of finding similar word vectors is of utmost essence.
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledMachineTranslation,
title = {Machine Translation},
author = {Chadha, Aman},
journal = {Distilled Notes for the Natural Language Processing Specialization on Coursera (offered by deeplearning.ai)},
year = {2020},
note = {\url{https://aman.ai}}
}