Coursera-ML • Unsupervised Learning (Work in Progress)
Unsupervised Learning
- After supervised learning, the most common form of machine learning is unsupervised learning. In unsupervised learning, we are given data without any output labels \(y\).
- Data comes with inputs \(x\) but no outputs \(y\) and the algorithm has to find structure in this data.
- Let’s take our earlier breast cancer prediction problem for an example.
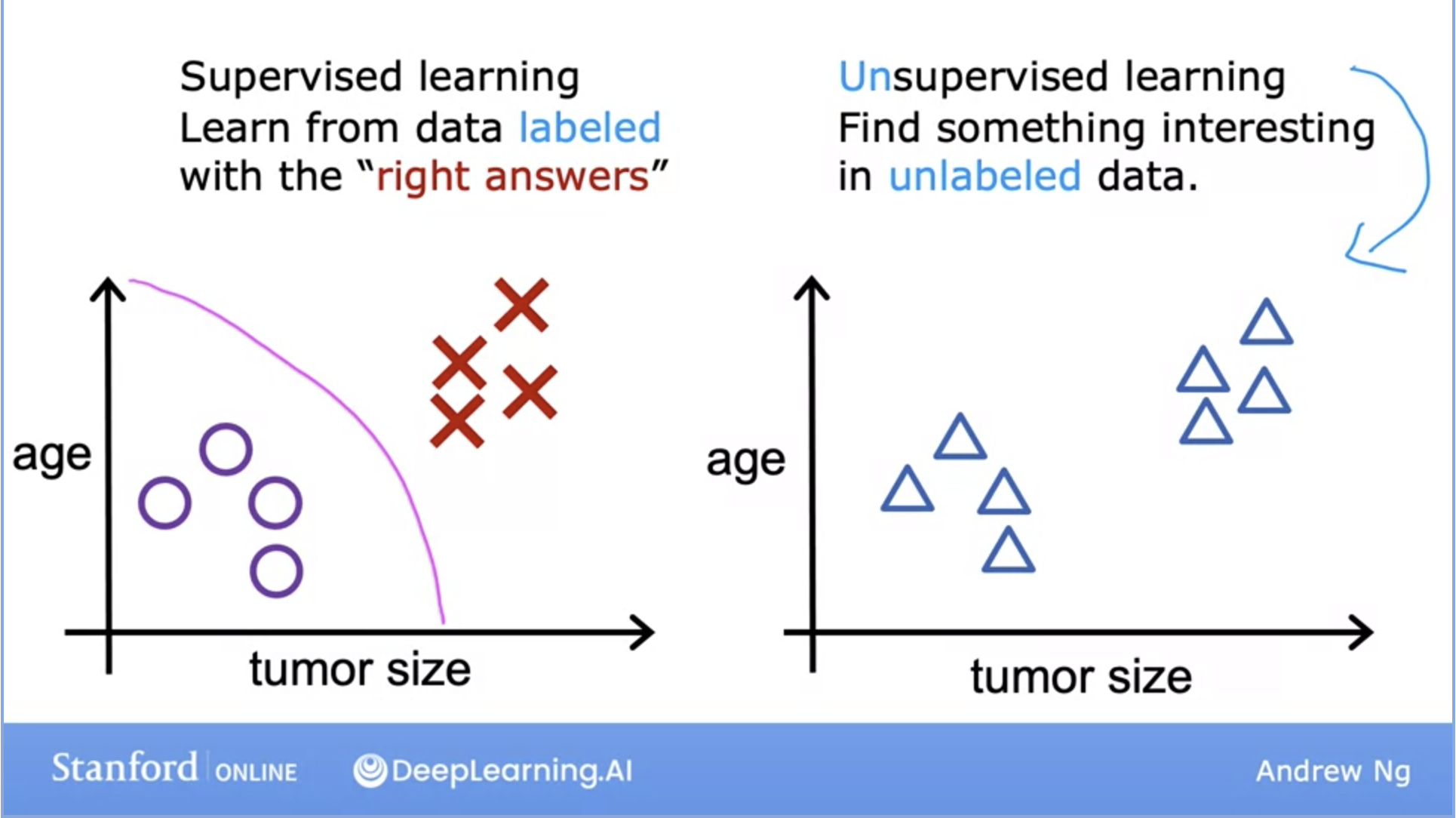
- We’re not asked here to predict whether the tumor is malignant or benign because we are not given any labels of which tumor is which.
- Instead, our job is to find some pattern, or some data, or just something interesting within this unlabeled dataset.
- The reason this is called unsupervised learning is that we are not asking the algorithm to give us a “right answer”.
- In this example, our unsupervised algorithm might decide there are two clusters, with one group here and one there.
-
This is a specific type of unsupervised learning algorithm called clustering algorithm because it places the unlabelled data into different clusters.
-
Clustering algorithm
- Clustering groups similar data points together.
- Clustering has many use cases:
- It is used in Google News! Google News looks at 100’s of stories every day and clusters them together.
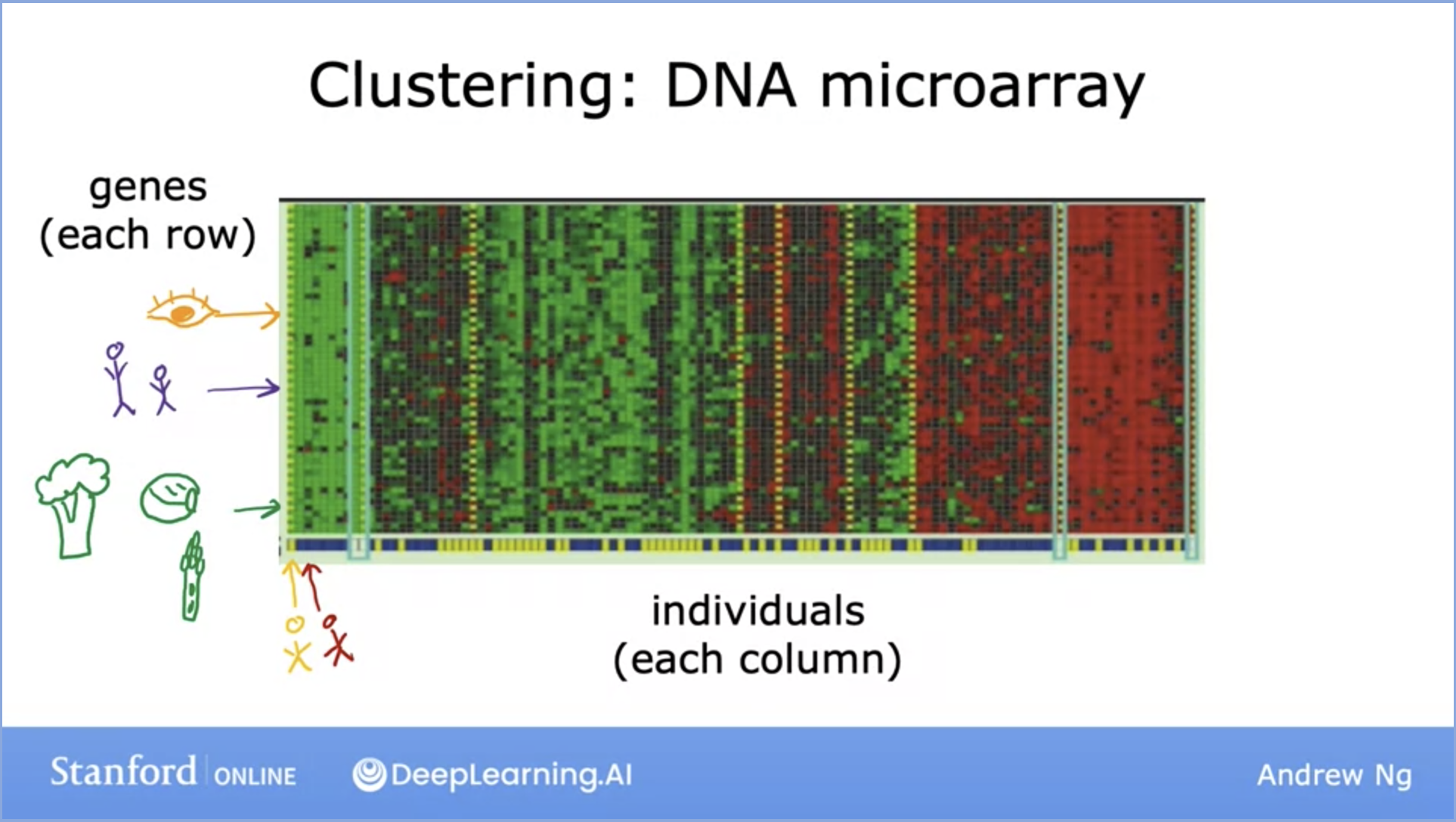
- It is used in DNA microarray clustering. The red here might represent a gene that affects eye color, or the green here is
a gene that affects how tall someone is.
- You can run a clustering algorithm to group different types of individuals together based on categories the algorithm has automatically decided.
- It is used in grouping customers in different market segments to better understand a company’s consumer base. This could help in improving marketing strategies for each group.
Anomaly detection algorithm
- Find unusual data points. This could be used to detect fraud in bank transactions.
Dimensionality reduction
- Compress data using fewer numbers.